Contents
- Introduction to Text Reuse
- Prerequisites
- Installing Passim
- Preparing Data for Passim
- Running Passim
- Using Passim’s Output
- Further readings
- Acknowledgements
- Bibliography
In this lesson you will be introduced to the automatic detection of text reuse with the Passim library. You will learn how to install and run Passim and its dependencies, how to prepare your texts as input files suitable for use with Passim and, finally, how to process the output generated by Passim to carry out basic analyses.
This lesson targets digital humanities (DH) practitioners without any prior knowledge of text reuse, but with a working knowledge of bash scripting and Python as well as some data manipulation. For tutorials on bash scripting and Python, you can refer to the Programming Historian “Introduction to the Bash Command Line tutorial and the library of current Python lessons on the Programming Historian website.
This lesson includes an overview of Passim, an open source tool for automatic text reuse detection. While the tool has been used in a number of small and large DH projects, it lacks a user-friendly documentation with examples and set up instructions, a gap that we aim to fill with this Programming Historian lesson.
Introduction to Text Reuse
Text reuse can be defined as “the meaningful reiteration of text, usually beyond the simple repetition of common language” (Romanello et al. 2014). It is such a broad concept that it can be understood at different levels and studied in a large variety of contexts. In a publishing or teaching context, for example, instances of text reuse can constitute plagiarism should portions of someone else’s text be repeated without appropriate attribution. In the context of literary studies, text reuse is often just a synonym for literary phenomena like allusions, paraphrases and direct quotations.
The following list includes just some of the libraries available that perform automatic text reuse detection:
- The R textreuse package (R) written by Lincoln Mullen
- TRACER (Java) developed by Marco Büchler and colleagues
- Basic Local Alignment Search Tool (BLAST)
- Tesserae (PHP, Perl)
- TextPAIR (Pairwise Alignment for Intertextual Relations)
- Passim (Scala) developed by David Smith (Northeastern University)
For this tutorial we chose the Passim library for three main reasons. Firstly, it can be adapted to a variety of use cases as it works well on a small text collection as well as on a large-scale corpus. Secondly, while the documentation for Passim is extensive, because of its relatively advanced user audience, a more user-centered step-by-step tutorial about detecting text reuse with Passim would be beneficial to the user community. Lastly, the following examples illustrate the variety of scenarios in which text reuse is a useful methodology:
- To determine whether a digital library contains multiple editions of the same work(s)
- To find quotations in a text, provided that the target works are known (e.g. find quotations of the Bible within 17c English literature)
- To study the virality and spread of texts (e.g. Viral Texts by Cordell and Smith for historical newspapers)
- To identify (and possibly filter out) duplicate documents within a text collection before performing further processing steps (e.g. topic modelling as illustrated by Schofield et al. (2017))
For these reasons, Passim is usually a great choice. It will help you automate the search for repeated text passages in a corpus — whether these are running ads in newspapers, multiple copies of the same poem, or direct (and slightly indirect) quotations in someone else’s book. Text reuse detection as implemented in Passim aims at identifying these copies and repetitions automatically, and yields clusters of passages that were deemed to be related with one another. Ultimately, what a cluster contains can vary a lot and will depend on your research question. For example, Passim can group together copies of the same article that differ only with respect to optical character recognition (OCR) errors, but it can also help to retrieve texts that share the same journalistic template, such as horoscopes or advertisements.
Prerequisites
This tutorial requires the following:
- A basic understanding of Bash scripts. For readers needing a review on Bash scripts, read the Programming Historian lesson “Introduction to the Bash Command Line”.
- Knowledge of JSON. To learn more about JSON, read the Programming Historian lesson “Reshaping JSON with jq”.
Moreover, while a basic understanding of Python — and a working Python installation — are not strictly needed to work with Passim, they are required to run some parts of this tutorial (e.g. the Jupyter notebook with data exploration, or the Early English Books Online (EEBO) data preparation script). If you are not familiar with Python, please read the Programming Historian lesson “Python Introduction and Installation”.
Note that installing Passim on Windows is more arduous than macOS or Linux. As a result, we recommend using macOS or Linux (or a virtual environment) for this lesson.
Installing Passim
Installing Passim requires installing the following software:
But why are all these dependencies needed?
Passim is written in a programming language called Scala. To execute a software written in Scala, its sources need to be compiled into an executable JAR file, which is performed by sbt, Scala’s interactive build tool. Finally, since Passim is designed to work also on large-scale text collections (with several thousands or millions of documents), behind the scenes it uses Spark, a cluster-computing framework written in Java. Using Spark allows Passim to handle the distributed processing of certain parts of the code, which is useful when handling large amounts of data. The Spark glossary is a useful resource to learn basic Spark terminology (words like “driver”, “executor”, etc.) but learning this terminology may not be necessary if you are running Passim on a small dataset.
Before installing this set of software, you’ll need to download the Passim source code from GitHub:
>>> git clone https://github.com/dasmiq/Passim.git
If you are not familiar with Git and GitHub, we recommend reading the Programming Historian lesson “An Introduction to Version Control Using GitHub Desktop”.
macOS instructions
These instructions are aimed at users of Apple’s macOS and were tested under version 10.13.4 (a.k.a. High Sierra).
Check Java Installation
Ensure that you have Java Development Kit 8 by typing the following command in a new Terminal window:
>>> java -version
If the output of this command looks similar to the following example, then Java 8 is installed on your machine.
openjdk version "1.8.0_262"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_262-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.262-b10, mixed mode)
Installing Java 8
In case another version of Java is installed on your machine, follow the following steps to install Java 8 alongside the existing Java version.
This is important so as not to break already installed software that needs more recent Java versions.
-
Install the
brewpackage manager by following installation instructions on the Brew.sh website. Once the installation is completed, runbrew --helpto verify it works. -
Use
brewto install Java 8.
>>> brew cask install adoptopenjdk/openjdk/adoptopenjdk8
Verify that Java 8 is installed.
>>> /usr/libexec/java_home -V
This command should output something similar to the following:
Matching Java Virtual Machines (2):
13.0.2, x86_64: "Java SE 13.0.2" /Library/Java/JavaVirtualMachines/jdk-13.0.2.jdk/Contents/Home
1.8.0_262, x86_64: "AdoptOpenJDK 8" /Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home
/Library/Java/JavaVirtualMachines/jdk-13.0.2.jdk/Contents/Home
- Install
jenv, a tool that allows you to manage multiple Java versions installed on the same machine, and to easily switch between them.
>>> brew install jenv
To be able to call jenv without specifying the executable’s full path don’t forget to add jenv to your $PATH environment variable by opening the file ~/.bashrc with your favorite text editor and adding the following lines at the end of the file:
# activate jenv
export PATH="$HOME/.jenv/bin:$PATH"
eval "$(jenv init -)"
After adding these lines, you need to open another terminal window or run the following line so that the $PATH variable is updated with the change you just made (the command source triggers the reload of your bash configuration).
>>> source ~/.bashrc
Once installed, add the existing Java versions to jenv (i.e. those listed by the command /usr/libexec/java_home -V):
# your mileage may vary, so make sure you replace this path
# with the actual path to the JAVA_HOME in your machine
>>> jenv add /Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home
Now you can set the default version of Java for this project by running the following:
>>> jenv local 1.8
# verify
>>> java -version
Compiling Passim From the Sources (macOS)
Passim is written in a programming language called Scala. Before being able to execute a software written in Scala, its sources need to be compiled. This task is performed by sbt, the Interactive Build Tool.
To determine whether sbt is installed on your machine, run the following command:
>>> sbt about
If this command prints bash: sbt: command not found it means sbt is not installed.
However, Passim comes with a useful script (build/sbt) that will download and install SBT automatically before compiling the sources from Passim.
NB: Using an external (i.e. already installed) SBT may lead to issues, we recommend the following method for compiling Passim.
To compile the program, run the following command from the directory where you’ve previously cloned Passim’s GH repository:
>>> cd Passim/
>>> build/sbt package
This command will take some time (around 3 minutes on a modern connection), but will let you know of the progress. As your computer starts downloading required files, a log will be printed on screen. At the end of this process, sbt will have created a .jar archive contaning the compiled sources for Passim. This file is found in the target directory: target/scala-2.11/Passim_2.11-0.2.0.jar. Depending on the version of Scala and Passim, the actual path might be slightly different on your computer.
The bin directory contains a Passim file: this is the executable that will launch Passim. In order for your computer the location of this file, and thus for it to recognise the Passim command, we need to add the path to the PATH environment variable.
# replace /home/simon/Passim for the directory where you installed Passim
>>> export PATH="/home/simon/Passim/bin:$PATH"
To add the path permanently to the PATH environment variable, open the file ~/.bashrc with your favorite text editor and add the following line anywhere in the file (then execute source ~/.bashrc to apply this change):
# replace "/home/simon/Passim" for the directory where you installed Passim
export PATH="/home/simon/Passim/bin:$PATH"
Installing Spark
-
Navigate to the download section of the Spark website and select Spark release version ‘3.x.x’ (where ‘x’ means any version that starts with ‘3.’), and package type ‘Pre-built for Apache Hadoop 2.7’ from the dropdown menus.
- Extract the compressed binaries to a directory of your choice (e.g.
/Applications):>>> cd /Applications/ >>> tar -xvf ~/Downloads/spark-3.1.x-bin-hadoop2.7.tgz - Add the directory where you installed Spark to your
PATHenvironment variable. To do so temporarily run the following command:
>>> export PATH="/Applications/spark-3.1.x-bin-hadoop2.7:$PATH"
To add the path installation directory permanently to your PATH environment variable, open the file ~/.bashrc with your favorite text editor and add the following line anywhere in the file:
export PATH="/Applications/spark-3.1.x-bin-hadoop2.7:$PATH"
After editing ~/.bashrc, open another terminal window or run the following command:
>>> source ~/.bashrc
Linux instructions
These instructions are aimed at Debian-based distributions (Debian, Ubuntu, Linux Mint, etc.). If you run another type of distribution (Fedora, Gentoo, etc.), replace the distribution-specific commands (eg apt) with those used by your specific distribution.
Check Java Installation
To ensure that you have the Java Development Kit 8 installed, run the following command:
>>> java -version
If the command above returns 1.8.0_252 or similar, then you have Java Development Kit 8 installed (the 8 lets you know you have correct kit installed and selected by default). If your output looks different, choose one of the following commands accordingly:
# If you don't, install it
>>>> apt install openjdk-8-jdk
# if your *default* JDK is not version 8
>>> sudo update-alternatives --config java
Compiling Passim from the Sources
Refer to the compilation instructions for macOS, as they are the same for the Linux environment.
Installing Spark
- Download the Spark binaries by using
wget:>>> wget -P /tmp/ http://apache.mirrors.spacedump.net/spark/spark-3.1.2/spark-3.1.2-bin-hadoop2.7.tgz - Extract the compressed binaries to a directory of your choice:
>>> tar -xvf /tmp/spark-3.1.2-bin-hadoop2.7.tgz -C /usr/local/ - Add the directory where you installed Spark to your
PATHenvironment variable. To add the directory to yourPATHenvironment variable temporarily, run the following command:>>> export PATH="/usr/local/spark-3.1.2-bin-hadoop2.7/bin:$PATH" # note that "/usr/local/" is the directory specified above, if you specified another directory change this accordinglyTo add the directory to your
PATHenvironment variable permanently, open the file~/.bashrcwith your favorite text editor and add the following line anywhere in the file:>>> export PATH="/usr/local/spark-3.1.2-bin-hadoop2.7/bin:$PATH"After editing
~/.bashrc, you need to open another terminal window or run the following line so that yourPATHvariable is updated with the change you just made.>>> source ~/.bashrc
Verify the Installation
At this point you have installed Passim and all required packages on your machine. If you type Passim --help in the command line, you should see output similar to the following:
Ivy Default Cache set to: /Users/matteo/.ivy2/cache
The jars for the packages stored in: /Users/matteo/.ivy2/jars
:: loading settings :: url = jar:file:/Applications/spark-2.4.6-bin-hadoop2.7/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
com.github.scopt#scopt_2.11 added as a dependency
graphframes#graphframes added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-bb5bd11f-ba3c-448e-8f69-5693cc073428;1.0
confs: [default]
found com.github.scopt#scopt_2.11;3.5.0 in spark-list
found graphframes#graphframes;0.7.0-spark2.4-s_2.11 in spark-list
found org.slf4j#slf4j-api;1.7.16 in spark-list
:: resolution report :: resolve 246ms :: artifacts dl 4ms
:: modules in use:
com.github.scopt#scopt_2.11;3.5.0 from spark-list in [default]
graphframes#graphframes;0.7.0-spark2.4-s_2.11 from spark-list in [default]
org.slf4j#slf4j-api;1.7.16 from spark-list in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 3 | 0 | 0 | 0 || 3 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-bb5bd11f-ba3c-448e-8f69-5693cc073428
confs: [default]
0 artifacts copied, 3 already retrieved (0kB/6ms)
20/07/17 15:23:17 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
20/07/17 15:23:19 INFO SparkContext: Running Spark version 2.4.6
20/07/17 15:23:19 INFO SparkContext: Submitted application: Passim.PassimApp
20/07/17 15:23:19 INFO SecurityManager: Changing view acls to: matteo
20/07/17 15:23:19 INFO SecurityManager: Changing modify acls to: matteo
20/07/17 15:23:19 INFO SecurityManager: Changing view acls groups to:
20/07/17 15:23:19 INFO SecurityManager: Changing modify acls groups to:
20/07/17 15:23:19 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(matteo); groups with view permissions: Set(); users with modify permissions: Set(matteo); groups with modify permissions: Set()
20/07/17 15:23:20 INFO Utils: Successfully started service 'sparkDriver' on port 62254.
20/07/17 15:23:20 INFO SparkEnv: Registering MapOutputTracker
20/07/17 15:23:20 INFO SparkEnv: Registering BlockManagerMaster
20/07/17 15:23:20 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
20/07/17 15:23:20 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
20/07/17 15:23:20 INFO DiskBlockManager: Created local directory at /private/var/folders/8s/rnkbnf8549qclh_gcb_qj_yw0000gv/T/blockmgr-f42fca4e-0a6d-4751-8d3b-36db57896aa4
20/07/17 15:23:20 INFO MemoryStore: MemoryStore started with capacity 366.3 MB
20/07/17 15:23:20 INFO SparkEnv: Registering OutputCommitCoordinator
20/07/17 15:23:20 INFO Utils: Successfully started service 'SparkUI' on port 4040.
20/07/17 15:23:20 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.0.24:4040
20/07/17 15:23:20 INFO SparkContext: Added JAR file:///Users/matteo/.ivy2/jars/com.github.scopt_scopt_2.11-3.5.0.jar at spark://192.168.0.24:62254/jars/com.github.scopt_scopt_2.11-3.5.0.jar with timestamp 1594992200488
20/07/17 15:23:20 INFO SparkContext: Added JAR file:///Users/matteo/.ivy2/jars/graphframes_graphframes-0.7.0-spark2.4-s_2.11.jar at spark://192.168.0.24:62254/jars/graphframes_graphframes-0.7.0-spark2.4-s_2.11.jar with timestamp 1594992200489
20/07/17 15:23:20 INFO SparkContext: Added JAR file:///Users/matteo/.ivy2/jars/org.slf4j_slf4j-api-1.7.16.jar at spark://192.168.0.24:62254/jars/org.slf4j_slf4j-api-1.7.16.jar with timestamp 1594992200489
20/07/17 15:23:20 INFO SparkContext: Added JAR file:/Users/matteo/Documents/Passim/target/scala-2.11/Passim_2.11-0.2.0.jar at spark://192.168.0.24:62254/jars/Passim_2.11-0.2.0.jar with timestamp 1594992200489
20/07/17 15:23:20 INFO Executor: Starting executor ID driver on host localhost
20/07/17 15:23:20 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 62255.
20/07/17 15:23:20 INFO NettyBlockTransferService: Server created on 192.168.0.24:62255
20/07/17 15:23:20 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
20/07/17 15:23:20 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.0.24, 62255, None)
20/07/17 15:23:20 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.0.24:62255 with 366.3 MB RAM, BlockManagerId(driver, 192.168.0.24, 62255, None)
20/07/17 15:23:20 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.0.24, 62255, None)
20/07/17 15:23:20 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.0.24, 62255, None)
Usage: Passim [options] <path>,<path>,... <path>
--boilerplate Detect boilerplate within groups.
--labelPropagation Cluster with label propagation.
-n, --n <value> index n-gram features; default=5
-l, --minDF <value> Lower limit on document frequency; default=2
-u, --maxDF <value> Upper limit on document frequency; default=100
-m, --min-match <value> Minimum number of n-gram matches between documents; default=5
-a, --min-align <value> Minimum length of alignment; default=20
-L, --min-lines <value> Minimum number of lines in boilerplate and docwise alignments; default=5
-g, --gap <value> Minimum size of the gap that separates passages; default=100
-c, --context <value> Size of context for aligned passages; default=0
-o, --relative-overlap <value>
Minimum relative overlap to merge passages; default=0.8
-M, --merge-diverge <value>
Maximum length divergence for merging extents; default=0.3
-r, --max-repeat <value>
Maximum repeat of one series in a cluster; default=10
-p, --pairwise Output pairwise alignments
-d, --docwise Output docwise alignments
--linewise Output linewise alignments
-N, --names Output names and exit
-P, --postings Output postings and exit
-i, --id <value> Field for unique document IDs; default=id
-t, --text <value> Field for document text; default=text
-s, --group <value> Field to group documents into series; default=series
-f, --filterpairs <value>
Constraint on posting pairs; default=gid < gid2
--fields <value> Semicolon-delimited list of fields to index
--input-format <value> Input format; default=json
--schema-path <value> Input schema path in json format
--output-format <value> Output format; default=json
--aggregate Output aggregate alignments of consecutive seqs
-w, --word-length <value>
Minimum average word length to match; default=2
--help prints usage text
<path>,<path>,... Comma-separated input paths
<path> Output path
20/07/17 15:23:20 INFO SparkContext: Invoking stop() from shutdown hook
20/07/17 15:23:20 INFO SparkUI: Stopped Spark web UI at http://192.168.0.24:4040
20/07/17 15:23:21 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
20/07/17 15:23:21 INFO MemoryStore: MemoryStore cleared
20/07/17 15:23:21 INFO BlockManager: BlockManager stopped
20/07/17 15:23:21 INFO BlockManagerMaster: BlockManagerMaster stopped
20/07/17 15:23:21 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
20/07/17 15:23:21 INFO SparkContext: Successfully stopped SparkContext
20/07/17 15:23:21 INFO ShutdownHookManager: Shutdown hook called
20/07/17 15:23:21 INFO ShutdownHookManager: Deleting directory /private/var/folders/8s/rnkbnf8549qclh_gcb_qj_yw0000gv/T/spark-dbeee326-7f37-475a-9379-74da31d72117
20/07/17 15:23:21 INFO ShutdownHookManager: Deleting directory /private/var/folders/8s/rnkbnf8549qclh_gcb_qj_yw0000gv/T/spark-9ae8a384-b1b3-49fa-aaff-94ae2f37b2d9
Preparing Data for Passim
The goal of using Passim is to automate the search for repeated text passages in a corpus. For example, a newspaper corpus contains multiple copies of the same article, identical or with slight differences from one another, as well as repetitions of smaller portions of a newspaper page (e.g. advertisement, event listings, etc.).
As the documentation for Passim specifies “the input to Passim is a set of documents. Depending on the kind of data you have, you might choose documents to be whole books, pages of books, whole issues of newspapers, individual newspaper articles, etc. Minimally, a document consists of an identifier string and a single string of text content” (Refer to the minimal JSON input example in the next section for more information about the structure of input for Passim).
Figure 1 gives a schematic representation of input and output data for Passim. Given an input set of documents, divided into document series, Passim will attempt to identify reuse of text from documents in different series, and not within these series. In the case of a newspaper corpus, articles from the same newspaper will belong to the same document series, as we are not interested in detecting reuse within the same newspaper, but across different newspapers.
Ultimately, what constitutes a document, and how these documents should be divided into series, are the choices you’ll need to make when preparing your data for Passim. Naturally, the decision on what constitutes a series of documents is directly dependent on your goals or research questions. Finding quotations of the Bible in a corpus of books is a “one-to-many” case of text reuse detection, which requires documents to be grouped into two series (bible and non_bible). Instead, the comparison between multiple editions of the Bible (also known as collation) can be seen a “many-to-many” case, where each edition will correspond to and constitute a series of documents (e.g. pages). If your research questions change at some point, thus requiring a re-definition of document series, you will need also to produce new input data for Passim to reflect this change.
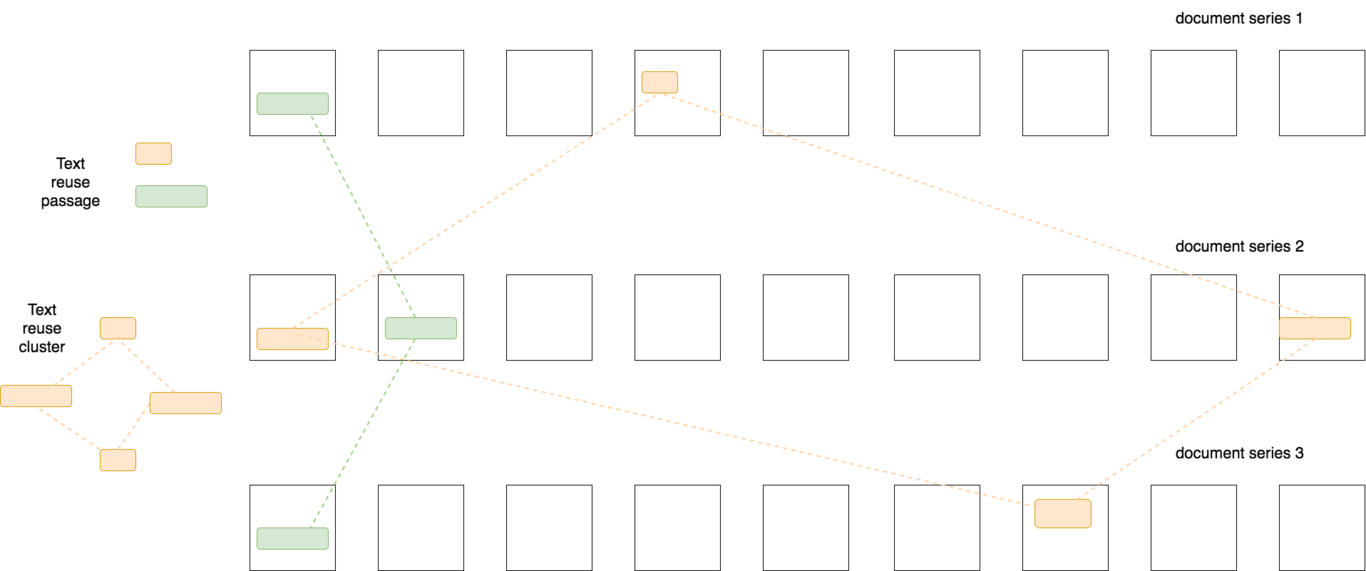
Figure 1. Schematic representation of text reuse clusters; each cluster consists of similar passages found in several series of documents.
Basic JSON format
The input format for Passim consists of JSON documents in the JSON lines format (i.e. each line of text contains a single JSON document).
The following file content for a file named test.json illustrates a minimal example of the input format for Passim:
{"id": "d1", "series": "abc", "text": "This is the text of a document."}
{"id": "d2", "series": "def", "text": "This is the text of another document."}
The fields id, series and text are the only fields required by Passim. Given this file as input, the software will try to detect text reuse between documents in the series abc and those in the series def, on the basis of the contents in text.
Throughout this tutorial we will be using the command-line tool jq to inspect and do some basic process on both input and output JSON data. Note that, if you don’t have jq installed, you’ll need to execute sudo apt-get install jq under Ubuntu or brew install jq under macOS (for other operating systems refer to the official JQ installation page).
For example, to select and print the field series of your input test.json, run the following command:
>>> jq '.series' test.json
# this will print
"abc"
"def"
Note: If you are using jq to look at your JSON data, you need to use the --slurp parameter whenever you want to treat the content of one or more JSON line files as a single array of JSON documents and apply some filters to it (e.g. to select and print only one document, use the following command jq --slurp '.[-1]' test.json). Otherwise jq will treat each document separately thus causing the following error:
>>> jq '.[0]' test.json
jq: error (at <stdin>:1): Cannot index string with string "series"
jq: error (at <stdin>:2): Cannot index string with string "series"
A Note on Packaging Data
Depending one the total size of your data, it may be a good idea to store Passim input files as compressed archives. Passim supports several compression schemes like .gzip and .bzip2. Note that a compressed datastream will be slower to process than an uncompressed one, so using this option will only be beneficial if your data is large (i.e. gigabytes of text), if you have access to many computing cores, or have a limited amount of disk space.
This command (or, better, chain of commands) will output the first document in a bzip2-compressed JSON lines file (some fields have been truncated for the sake of readability):
>>> bzcat impresso/GDL-1900.jsonl.bz2 | jq --slurp '.[0]'
And will output the following:
{
"series": "GDL",
"date": "1900-12-12",
"id": "GDL-1900-12-12-a-i0001",
"cc": true,
"pages": [
{
"id": "GDL-1900-12-12-a-p0001",
"seq": 1,
"regions": [
{
"start": 0,
"length": 13,
"coords": {
"x": 471,
"y": 1240,
"w": 406,
"h": 113
}
},
{
"start": 13,
"length": 2,
"coords": {
"x": 113,
"y": 1233,
"w": 15,
"h": 54
}
},
...
]
}
],
"title": "gratuitement ,la §azette seia envoyée",
"text": "gratuitement\n, la § azette\nseia envoyée\ndès ce jour au 31 décembre, aux personnes\nqui s'abonneront pour l'année 1901.\nLes abonnements sont reçus par l'admi-\nnistration de la Gazette de Lausanne et dans\ntous les bureaux de poste.\n"
}
Custom JSON format
(Note: This subsection is not strictly necessary to run Passim, as the second case study will showcase. Nonetheless, these steps may be useful to readers with advanced needs with the regards to the format and structure of input data.)
There are cases where you may want to include additional information (i.e. JSON fields) in each input document, in addition to the required ones (id, series, text). As an example, when working with OCR data you may want to pass image coordinate information alongside the article text. Passim does support the use of input data that follow a custom JSON format as behind the scenes it relies on Spark to infer the structure of the input data (i.e. the JSON schema). Passim will not directly use these fields, but it will keep them in the produced output.
However, there may be cases where Spark fails to infer the correct structure of input data (e.g. by inferring a wrong data type for a given field). In these cases, you need to inform Passim about the correct schema of the input data.
The following example illustrates a step-by-step approach to troubleshooting this relatively rare situation where one needs to correct the inferred JSON schema. Passim comes with the command json-df-schema, which runs a (Python) script to infer the schema from any JSON input. The following steps are necessary to infer the structure from any JSON data:
- Install the necessary Python libraries.
>>> pip install pyspark - Extract an input example from one of our compressed input files.
# here we take the 3rd document in the .bz2 file # and save it to a new local file >>> bzcat impresso/data/GDL-1900.jsonl.bz2 | head | jq --slurp ".[2]" > impresso/data/impresso-sample-document.json - Ask
json-df-schemato infer the schema of our data from our sample file.>>> json-df-schema impresso/data/impresso-sample-document.json > impresso/schema/Passim.schema.orig
json-df-schema will try to guess the JSON schema of input data and output it to a file. The following example is what the schema generated by Passim (Passim.schema.orig) looks like:
{
"fields": [
{
"metadata": {},
"name": "cc",
"nullable": true,
"type": "boolean"
},
{
"metadata": {},
"name": "date",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "id",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "pages",
"nullable": true,
"type": {
"containsNull": true,
"elementType": {
"fields": [
{
"metadata": {},
"name": "id",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "regions",
"nullable": true,
"type": {
"containsNull": true,
"elementType": {
"fields": [
{
"metadata": {},
"name": "coords",
"nullable": true,
"type": {
"fields": [
{
"metadata": {},
"name": "h",
"nullable": true,
"type": "long"
},
{
"metadata": {},
"name": "w",
"nullable": true,
"type": "long"
},
{
"metadata": {},
"name": "x",
"nullable": true,
"type": "long"
},
{
"metadata": {},
"name": "y",
"nullable": true,
"type": "long"
}
],
"type": "struct"
}
},
{
"metadata": {},
"name": "length",
"nullable": true,
"type": "long"
},
{
"metadata": {},
"name": "start",
"nullable": true,
"type": "long"
}
],
"type": "struct"
},
"type": "array"
}
},
{
"metadata": {},
"name": "seq",
"nullable": true,
"type": "long"
}
],
"type": "struct"
},
"type": "array"
}
},
{
"metadata": {},
"name": "series",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "text",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "title",
"nullable": true,
"type": "string"
}
],
"type": "struct"
}
Passim has failed to recognize the coordinate field as containing integer values and it has interpreted as a long data type. At this point, we need to change the type of the sub-fields of coords (i.e. h, w, x, and y) from "type": "long" to "type": "integer". This type mismatch needs to be fixed, otherwise Passim will treat int values as if they were long, thus potentially leading to issues or inconsistencies in the generated output.
We can now save the schema for later into a new file (passim.schema) for later use. This schema is needed when processing the input data provided for the second case study presented in this lesson.
Running Passim
In this section we illustrate the usage of Passim with two separate case studies: 1) detecting Bible quotes in seventeent century texts and 2) detecting text reuse in a large corpus of historical newspapers. The first case study highlights some of the basics of using Passim, while the second case study contains many details and best practices that would be helpful for a large-scale text reuse project.
In the following table, we build on the original Passim documentation and explain some of the more useful parameters that this library offers. The case studies do not require you to master these parameters, so feel free to skip directly to the Downloading the Data section and come back to this section once you are comfortable enough to use Passim on your own data.
| Parameter | Default value | Description | Explanation |
|---|---|---|---|
--n |
5 | N-gram order for text-reuse detection | N-grams are chains of words of length N. This setting allows you to decide what type of n-gram (unigram, bigram, trigram…) Passim should use when creating a list of possible text reuse candidates. Setting this parameter to a lower value can help in the case of very noisy texts (i.e. when many words in a text are affected by one or more OCR errors). In fact, the longer the n-gram, the more likely it is to contain OCR mistakes. |
--minDF (-l) |
2 | Lower limit on document frequency of n-grams used | Since n-grams are used in Passim to retrieve document candidate pairs, an n-gram occurring only once is not useful as it will retrieve only one document (and not a pair). For this reason --minDF defaults to 2. |
--maxDF (-u) |
100 | Upper limit on document frequency of n-grams used. | This parameter will filter out n-grams that are too common, thus occurring many times in a given document. This value has an impact on the performances as it will reduce the number of document pairs retrieved by Passim that will need to be compared. |
--min-match (-m) |
5 | Minimum number of matching n-grams between two documents | This parameter allows you to decide how many n-grams must be found between two documents. |
--relative-overlap (-o) |
0.8 | Proportion that two different aligned passages from the same document must overlap to be clustered together, as measured on the longer passage | This parameter determines the degree of string similarity two passages need to have in order to be clustered together. In the case of very noisy texts, it may be desirable to set this parameter to a smaller value. |
--max-repeat (-r) |
10 | Maximum repeat of one series in a cluster | This paramter allows you to specify how much a given series can be present in a cluster. |
Downloading the data
Sample data needed to run the command examples in the two case studies can be downloaded from the dedicated GitHub repository. Before continuing with the case studies, download a local copy of the data by cloning the repository.
>>> git clone https://github.com/impresso/PH-Passim-tutorial.git
Alternatively, it is possible to download the data for this lesson from Zenodo at the address https://zenodo.org/badge/latestdoi/250229057.
Case study 1: Bible Quotes in Seventeenth Century Texts
In this first case study, we will look at text reuse using texts taken from EEBO-TCP Phase I, the publicly available keyed-in version of Early English Books Online provided by the Text Creation Partnership. This case study is a special case of text reuse, as we are not focusing at inter-authors text reuse, but rather at the influence a single book — in this case, the Bible in its published-in-1611 King James version — had on several authors. Can we detect what documents contain extracts from the Bible?
As this is a small-scale example of what an actual research question making use of text reuse methods could look like, we will only use some of the 25,368 works available in EEBO-TCP, taken randomly. This smaller selection size should also allow anyone reading this tutorial to run this example on their personal laptop. Ideally, we recommend using a corpus such as Early Modern Multiloquent Authors (EMMA), compiled by the University of Antwerp’s Mind Bending Grammars project, should someone want to properly study the use of Bible quotes in seventeenth century texts. This corpus has the advantage of providing hand-curated metadata in an easily parseable format, allowing any researcher to focus on specific authors, periods, etc.
Extracting the Data
At the root of the newly-created directory is a JSON file: passim_in.json. This file contains all our data, in the format described above: one document per line (text), structured with the bare minimum of required metadata (id, series). As this is a small file, we encourage you to open the file using a text editor such as Notepad++ on Windows or Sublime on Linux/macOS to familiarise yourself with how the data is formatted. Because our case study focuses on the detection of Bible passages in several documents and not on text reuse within all documents, we have formatted the data so that the series field contains bible for the Bible (last line of our JSON file), and not_bible for all other documents. Passim does not analyse documents that belong to the same series, so this effectively tells the software to only compare all documents with the Bible — not with each other.
The accompanying Github repository contains a Python script to transform EEBO-TCP into the JSON format required by Passim and used in this lesson. We encourage the readers to reuse it and adapt it to their needs.
Running Passim
Create a directory where you want to store the output of Passim (we use Passim_output_bible but any name will work). If you decide to use the default Passim_output_bible directory, ensure you remove all of its content (i.e. pre-computed Passim output) either manually or by running rm -r ./eebo/Passim_output_bible/*.
As we will see in more detail in the second use case, Passim, through Spark, allows for many options. By default Java does not allocate much memory to its processes, and running Passim even on very little datasets will cause Passim to crash because of an OutOfMemory error — even if you have a machine with a lot of RAM. To avoid this, when calling Passim we add some additional parameters that will tell Spark to use more RAM for its processes.
You are now ready to go forward with your first text reuse project.
-
Move to the sub-directory
eeboby executing the commandcd eebo/, starting from the directory where, earlier on, you cloned the repositoryPH-Passim-tutorial. -
Run the following command and go have a cup of your favorite hot beverage:
>>> SPARK_SUBMIT_ARGS='--master local[12] --driver-memory 8G --executor-memory 4G' passim passim_in.json passim_output_bible/
For now, do not worry about the additional arguments SPARK_SUBMIT_ARGS='--master local[12] --driver-memory 8G --executor-memory 4G'; in the section “Case Study 2” we will explain them in detail.
This test case takes approximatively eight minutes on a recent laptop with eight threads. You can also follow the progress of the detection at http://localhost:4040 — an interactive dashboard created by Spark (Note: the dashboard will shut down as soon as Passim has finished running).
Case study 2: Text Reuse in a large corpus of historical newspapers
The second case study is drawn from impresso, a recent research project aimed at enabling critical text mining of newspaper archives with the implementation of a technological framework to extract, process, link, and explore data from print media archives.
In this project, we use Passim to detect text reuse at scale. The extracted text reuse clusters are then integrated into the impresso tool in two ways. First, in the main article reading view users can readily see which portions of an article were reused by other articles in the corpus. Second, users can browse through all clusters in a dedicated page (currently more than 6 million), perform full-text searches on their contents, and filter the results according to a number of criteria (cluster size, time span covered, lexical overlap, etc.).
More generally, detecting text reuse in a large-scale newspaper corpus can be useful in many of the following ways:
- Identify (and possibly filter out) duplicated documents before performing further processing steps (e.g. topic modelling)
- Study the virality and spread of news
- Study information flows, both within and across national borders
- to allow users discover which contents, within in their own collections, generated text reuse (e.g. famous political speeches, portions of national constitutions, etc.)
For this case study we consider a tiny fraction of the impresso corpus, consisting of one year’s worth of newspaper data (i.e. 1900) for a sample of four newspapers. The corpus contains 76 newspapers from Switzerland and Luxembourg, covering a time span of 200 years. The sample data necessary to run step by step this case study are contained in the folder impresso/.
Data preparation
The format used in impresso to store newspapers data is slightly different from Passim’s input format so we need a script to take care of transforming the former into the latter. While discussing how this script works goes well beyond the scope of this lesson, you can find the conversion script on the impresso GitHub repository should you be interested. The output of this script is one JSON line file per newspaper per year, compressed into a .bz2 archive for the sake of efficient storage. Examples of this format can be found in the directory impresso/data and shown in the following example:
>>> ls -la impresso/data/
EXP-1900.jsonl.bz2
GDL-1900.jsonl.bz2
IMP-1900.jsonl.bz2
JDG-1900.jsonl.bz2
Each newspaper archive is named after the newspaper identifier: for example, GDL stands for Gazette de Lausanne. In total, these four .bz2 files contain 92,000 articles through Passim, corresponding to all articles published in 1900 in the four sampled newspapers.
Sometimes it’s not easy to inspect data packaged in this way. But some Bash commands like bzcat and jq can help us. For example, with the following chain of commands we can find out how many documents (newspaper articles) are contained in each of the input files by counting their IDs:
>>> bzcat impresso/data/GDL-1900.jsonl.bz2 | jq --slurp '[.[] |del(.pages)| .id]|length'
28380
And similarly, in all input files:
>>> bzcat impresso/data/*-1900.jsonl.bz2 | jq --slurp '[.[] |del(.pages)| .id]|length'
92514
What these commands do is to read the content of the .bz2 file by means of bzcat and then pipe this content into jq which
- iterates through all docouments in the JSON line file
- for each document it removes the
pagesfield as it’s not needed and selects only theidfield - finally, with
lengthjqcomputes the size of the list of IDs created by the previous expression
Running Passim
To run the impresso data through Passim, execute the following command in a Terminal window:
SPARK_SUBMIT_ARGS='--master local[12] --driver-memory 10G --executor-memory 10G --conf spark.local.dir=/scratch/matteo/spark-tmp/' Passim --schema-path="impresso/schema/Passim.schema" "impresso/data/*.jsonl.bz2" "impresso/Passim-output/"
This command is made up of the following parameters:
SPARK_SUBMIT_ARGSpasses some configuration parameters to Spark, the library that takes care of parallel execution of processes.--master local[10]:localmeans we are running Spark in single machine-mode;[10]specifies the number of workers (or threads, in this specific case) over which processes should be distributed (local [*]will make use of the maximum number of threads);--executor-memory 4G: The equivalent of the maximum heap size when running a regular JAVA application. It’s the amount of memory that Spark allocates to each executor.--conf spark.local.dir=/scratch/matteo/spark-tmp/: A directory where Spark stores temporary data. When working with large datasets, it is important to specify a location with sufficient free disk space.
--schema-path: Specifies the path to the JSON schema describing the input data to be ran through Passim (see section “Custom JSON format” for more information about how to generate such schema).impresso/data/*.jsonl.bz2: Specifies the input files (i.e. all files contained inimpresso/data/with.jsonl.bz2in the file name);impresso/Passim-output/: Specifies where Passim should write its output
If you want to limit the processing to a couple of input files — for example to limit memory usage — you can specify the input using the following command:
impresso/data/{EXP-1900.jsonl.bz2,GDL-1900.jsonl.bz2}.jsonl.bz2
You can monitor Passim’s progress while running by pointing your browser to the address localhost:4040 where the Spark dashboard can be accessed (Figure 2).
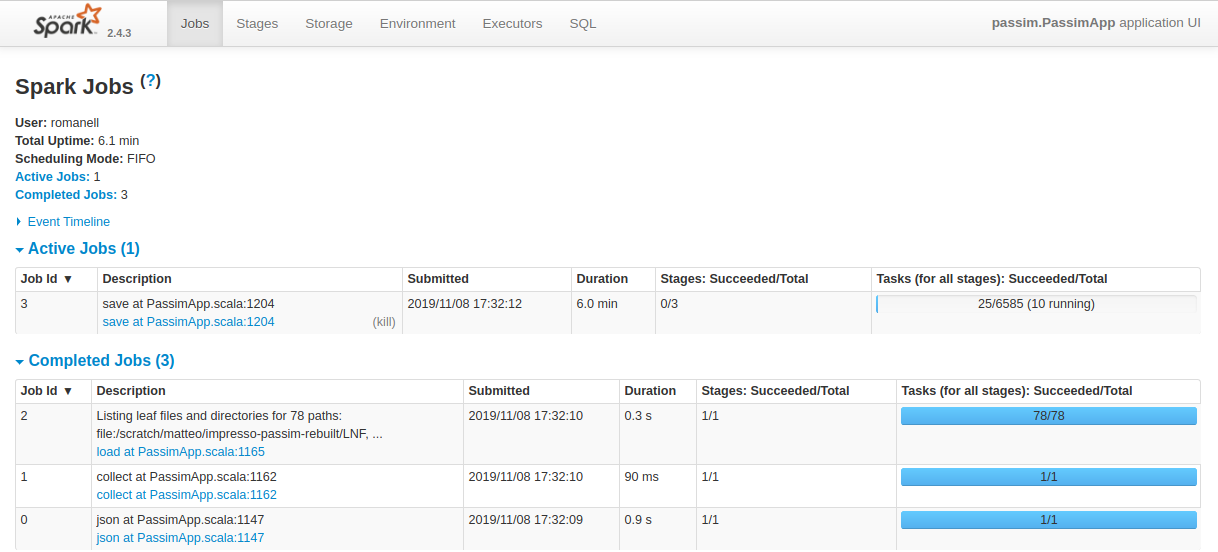
Figure 2. Screenshot of the Spark dashboard while running Passim.
Running Passim with eight workers (and 4 Gb of executor memory) takes about five minutes to process the 92,514 articles published in 1900 in the newspapers GDL, JDG, EXP, IMP (but your mileage may vary).
If you provide as input a folder with *.bz2 files, ensure these files are not found within subdirectories or Passim will not be able to find them automatically.
It is important that the output folder where Passim will write its output is empty. Especially when running the first experiments and getting familiar with the software it can very easily happen to specify a non-empty output folder. Specifying a non-empty output folder usually leads to an error as Passim processes the folder content and does not simply overwrite it.
Inspecting Passim’s Output
Once Passim has finished running, the output folder impresso/Passim-output/ will contain a sub-folder out.json/ with the extracted text reuse clusters. If you specified --output=parquet instead of --output=json, this sub-folder will be named out.parquet.
In the JSON output each document corresponds to a text reuse passage. Since passages are aggregated into clusters, each passage contains a field cluster with the ID of the cluster to which it belongs.
To obtain the total number of cluster, we can count the number of unique cluster IDs with the following one-line command:
>>> cat impresso/Passim-output/out.json/*.json | jq --slurp '[.[] | .cluster] | unique | length'
2721
Similarly, we can print the 100th cluster ID:
>>> cat impresso/Passim-output/out.json/*.json | jq --slurp '[.[] | .cluster] | unique | .[100]'
77309411592
And with a simple jq query we can print all passages belonging to this text reuse cluster:
>>> cat impresso/Passim-output/out.json/*.json | jq --slurp '.[] | select(.cluster==77309411592)|del(.pages)'
{
"uid": -6695317871595380000,
"cluster": 77309411592,
"size": 2,
"bw": 8,
"ew": 96,
"cc": true,
"date": "1900-07-30",
"id": "EXP-1900-07-30-a-i0017",
"series": "EXP",
"text": "nouvel accident de\nmontagne : Le fils dû guide Wyss, de\nWilderswil, âgé de 17 ans, accompagnait\nvendredi un touriste italien dans l'as-\ncension du Petersgrat En descendant sur\nle glacier de Tschingel, le jeune guide\ntomba dans une crevasse profonde de\n25 mètres. La corde était trop courte\npour l'en retirer, et des guides appelés\nà son secours ne parvinrent pas non\nplus à le dégager. Le jeune homme crie\nqu'il n'est pas blessé. Une nouvelle co-\nlonne de secours est partie samedi de\nLauterbrunnen.\nAarau, 28 juillet.\n",
"title": "DERNIÈRES NOUVELLES",
"gid": -8329671890893709000,
"begin": 53,
"end": 572
}
{
"uid": -280074845860282140,
"cluster": 77309411592,
"size": 2,
"bw": 2,
"ew": 93,
"cc": true,
"date": "1900-07-30",
"id": "GDL-1900-07-30-a-i0016",
"series": "GDL",
"text": "NOUVEAUX ACCIOENTS\nInterlaken. 29 juillet.\nLe fils du guide Wyss, de Wilderswil, âgé\nde dix-sept ans, accompagnait, vendredi, un\ntouriste italien dans l'ascension du Peters-\ngrat.\nEn descendant sur le glacier de Tschingel,\nU jeune guide tomba dans une crevasse pro-\nfonde de vingt-cinq mètres. La corde était trop\ncourte pour l'en retirer, et des guides appelés\nà son secours ne parvinrent pas non plus à le\ndégager. Le jeune homme crie qu'il n'est pas\nblessé. Une nouvelle colonne de secours est\npartie samedi de Lauterbrunnen.\nChamonix, 28 juillet.\n",
"title": "(Chronique alpestre",
"gid": 2328324961100034600,
"begin": 20,
"end": 571
}
As you can see from the output above, this cluster contains the same piece of news — a mountain accident which happened in Interlaken on 30 July 1900 — reported by two different newspapers on the very same day with slightly different words.
Using Passim’s Output
Since the usage of text reuse data ultimately depends on the research questions at hand — and there many possible applications of text reuse, as we have seen above — covering how to use Passim’s output falls beyond the scope of this lesson.
Code that ‘does something’ with the data output by Passim can be written in many different programming languages. Extracted clusters can be used to deduplicate documents in a corpus, or even collate together multiple witnesses of the same text, but this will entirely depend on the research context and specific use case.
To given an example of where to go next, for those who want to manipulate and further analyse text reuse data in Python, we provide a Jupyter notebook (explore-Passim-output.ipynb) that shows how to import Passim’s JSON output into a pandas.DataFrame and how to analyse the distribution of text reuse clusters in both uses cases presented above. For readers that are not familair with the Python library pandas, the Programming Historian lesson written by Charlie Harper on Visualizing Data with Bokeh and Pandas is a nice (and required) introductory reading.
The code contained and explained in the notebook will produce the two plots of Figures 3 and 4, showing how the sizes of text reuse clusters are distributed in the impresso and Bible data respectively.
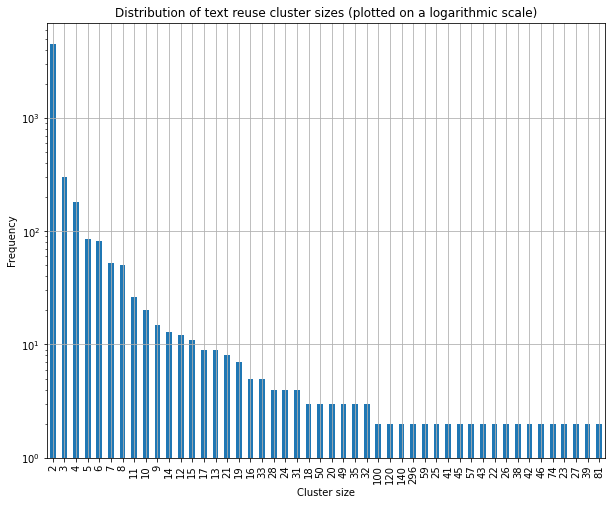
Figure 3. Distribution of text reuse cluster sizes in the impresso sample data.
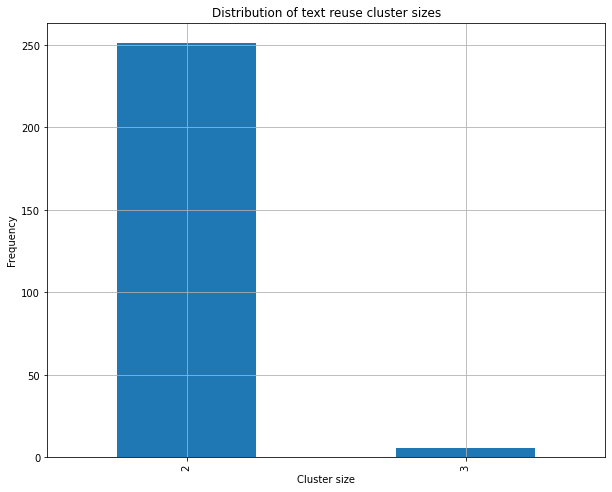
Figure 4. Distribution of text reuse cluster sizes in the Bible sample data.
As you can see from the plots, in both cases the majority of text reuse clusters contains at most two passages. In the impresso sample data, however, there is much more variance in the size of clusters, with 10% of them having a size comprised between 6 and 296 passages, as opposed to the Bible data where the maximum cluster size is 3.
Further readings
Passim
- Smith et al. (2015) introduce in detail the text reuse detection algorithm implemented in Passim
- Cordell (2015) applied Passim to study text reuse within a large corpus of American newspapers
textreuse
- Vogler et al. (2020) apply the
textreuseR package (Mullen 2016) to study the phenomenon of media concentration in contemporary journalism
TRACER
- Büchler et al. (2014) explain the algorithms for text reuse detection that are implemented in TRACER;
- Franzini et al. (2018) use and evaluate TRACER for the extraction of quotations from a Latin text (the Summa contra Gentiles of Thomas Aquinas)
BLAST
- Vierthaler et al. (2019) use the BLAST alignment algorithm to detect reuse in Chinese texts
- Vesanto et al. (2017) and Salmi et al. (2019) apply BLAST to a comprehensive corpus of newspapers published in Finland
Acknowledgements
A sincere thanks goes to Marco Büchler and Ryan Muther for reviewing this lesson, as well as to our colleagues Marten Düring and David Smith for their constructive feedback on an early version of this tutorial. Additional thanks go to Anna-Maria Sichani for serving as editor.
The authors warmly thank the newspaper Le Temps — owner of La Gazette de Lausanne (GDL) and the Journal de Genève (JDG) — and the group ArcInfo — owner of L’Impartial (IMP) and L’Express (EXP) — for accepting to share their data for academic purposes.
MR gratefully acknowledges the financial support of the Swiss National Science Foundation (SNSF) for the project impresso – Media Monitoring of the Past under grant number CR-SII5_173719. SH’s work was supported by the European Union’s Horizon 2020 research and innovation programme under grant 770299 (NewsEye). SH was affiliated with the University of Helsinki and the University of Geneva for most of this work, and is currently funded by the project Towards Computational Lexical Semantic Change Detection supported by the Swedish Research Council (20192022; dnr 2018-01184).
Bibliography
- Greta Franzini, Maria Moritz, Marco Büchler, Marco Passarotti. Using and evaluating TRACER for an Index fontium computatus of the Summa contra Gentiles of Thomas Aquinas. In Proceedings of the Fifth Italian Conference on Computational Linguistics (CLiC-it 2018). (2018). Link
- David A. Smith, Ryan Cordell, Abby Mullen. Computational Methods for Uncovering Reprinted Texts in Antebellum Newspapers. American Literary History 27, E1–E15 Oxford University Press, 2015. Link
- Ryan Cordell. Reprinting Circulation, and the Network Author in Antebellum Newspapers. American Literary History 27, 417–445 Oxford University Press (OUP), 2015. Link
- Daniel Vogler, Linards Udris, Mark Eisenegger. Measuring Media Content Concentration at a Large Scale Using Automated Text Comparisons. Journalism Studies 0, 1–20 Taylor & Francis, 2020. Link
- Lincoln Mullen. textreuse: Detect Text Reuse and Document Similarity. (2016). Link
- Marco Büchler, Philip R. Burns, Martin Müller, Emily Franzini, Greta Franzini. Towards a Historical Text Re-use Detection. 221–238 In Text Mining: From Ontology Learning to Automated Text Processing Applications. Springer International Publishing, 2014. Link
- Paul Vierthaler, Meet Gelein. A BLAST-based, Language-agnostic Text Reuse Algorithm with a MARKUS Implementation and Sequence Alignment Optimized for Large Chinese Corpora. Journal of Cultural Analytics (2019). Link
- Aleksi Vesanto, Asko Nivala, Heli Rantala, Tapio Salakoski, Hannu Salmi, Filip Ginter. Applying BLAST to Text Reuse Detection in Finnish Newspapers and Journals, 1771-1910. 54–58 In Proceedings of the NoDaLiDa 2017 Workshop on Processing Historical Language. Linköping University Electronic Press, 2017. Link
- Hannu Salmi, Heli Rantala, Aleksi Vesanto, Filip Ginter. The long-term reuse of text in the Finnish press, 1771–1920. 2364, 394–544 In CEUR Workshop Proceedings. (2019).
- Axel J Soto, Abidalrahman Mohammad, Andrew Albert, Aminul Islam, Evangelos Milios, Michael Doyle, Rosane Minghim, Maria Cristina de Oliveira. Similarity-Based Support for Text Reuse in Technical Writing. 97–106 In Proceedings of the 2015 ACM Symposium on Document Engineering. ACM, 2015. Link
- Alexandra Schofield, Laure Thompson, David Mimno. Quantifying the Effects of Text Duplication on Semantic Models. 2737–2747 In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2017. Link
- Matteo Romanello, Aurélien Berra, Alexandra Trachsel. Rethinking Text Reuse as Digital Classicists. Digital Humanities conference, 2014. Link
