
Contenidos
- Requisitos previos
- ¿Qué es el análisis de correspondencia?
- Comités parlamentarios de Canadá
- Preparando R para el análisis de correspondencia
- Los datos
- Análisis de correspondencia de los comités parlamentarios de Canadá 2006 y 2016.
- Interpretación del análisis de correspondencia
- ¿Expandió Trudeau la agenda sobre equidad para las mujeres en el parlamento?
- Análisis
- Conclusión
- Apéndice: Las matemáticas detrás del Análisis de Correspondencia
- Notas finales
El Análisis de Correspondencia (AC) produce un gráfico de dos o tres dimensiones basado en las relaciones que existen entre dos o más categorías de datos. Estas categorías pueden ser “miembros y clubes”, “palabras y libros” o “países y acuerdos comerciales”. Por ejemplo, un miembro de un club se puede corresponder con otro miembro de un club sobre la base de los clubes comunes a los que ambos pertenecen. Los miembros que asisten a los mismos clubes probablemente tengan más en común que aquellos que participan en clubes diferentes. En la misma línea, los clubes que comparten miembros tienen una mayor probabilidad de tener más en común que aquellos que tienen miembros diferentes.1
Distinguir estas correspondencias significativas puede ser muy difícil cuando hay muchos elementos en cada una de las categorías (por ejemplo, si tienes cientos de miembros distribuidos en docenas de clubes). El AC mide las correspondencias más fuertes a lo largo de un conjunto de datos y las proyecta en un espacio multidimensional que puede ser visualizado e interpretado. Usualmente, se crean gráficos con las dos primeras dimensiones, aunque es posible mostrar tres con visualizaciones en 3D.
En el AC, las relaciones entre los elementos se visualizan como distancias en un gráfico. Gracias a esto, es posible descubrir patrones que se basan en qué elementos de una categoría aparecen cercanos a los elementos de otra. Así, este tipo de análisis puede ser un buen primer paso para filtrar los principales patrones de un conjunto de datos de gran tamaño. Es una herramienta particularmente poderosa para entender información histórica contenida en colecciones digitales.
Después de leer este tutorial sabrás:
- Qué es el análisis de correspondencia y para qué se usa
- Cómo ejecutar un análisis de correspondencia usando el paquete de R FactoMineR
- Describir con precisión los resultados de un análisis de correspondencia
Requisitos previos
Este tutorial está pensado para personas con un nivel intermedio de programación. Asume un entendimiento básico de R y cierto conocimiento de estadística.
Como preparación, se pueden revisar los siguientes tutoriales ya publicados en Programming Historian:
- El de Taryn Dewar sobre Datos tabulares en R, que ofrece información sobre cómo instalar y configurar R
- El de Taylor Arnold y Lauren Tilton Procesamiento básico de textos en R, que puede servir como preparación también como preparación sobre el uso de este lenguaje de programación
- De la hermenéutica a las redes de datos: Extracción de datos y visualización de redes en fuentes históricas, de Marte Düring. Como el análisis de correspondencia es un tipo de análisis de redes sociales, vale la pena darle una mirada a este tutorial ya que contiene información útil sobre cómo estructurar datos para el análisis de redes
¿Qué es el análisis de correspondencia?
El análisis de correspondencia, también llamado “escalamiento multidimensional” o “análisis de red bivariado”, permite observar la interrelación de dos grupos en un gráfico bidimensional. Por ejemplo, fue reconocidamente utilizado por el sociólogo francés Pierre Bourdieu para mostrar cómo categorías sociales como ocupación influyen en la opinión política .2 Este tipo de análisis es especialmente poderoso como herramienta para encontrar patrones en conjuntos de datos de gran tamaño.
El análisis de correspondencia funciona con cualquier tipo de datos categóricos (es decir, datos que han sido agrupados en categorías). Partamos con un ejemplo simple. Si quisieras entender el rol que los tratados de comercio internacionales han tenido en la interconexión entre las naciones del G8, podrías crear una tabla para los países y las relaciones de libre comercio que han mantenido en un determinado período.
En el siguiente ejemplo, se muestra una pequeña selección de tratados de comercio (en azul), que incluye el Espacio Económico Europeo (EEE), el Acuerdo Económico y Comercial Global entre la Unión Europea y Canadá (AECG), el Tratado de Libre Comercio de América del Norte (TLCAN), el Acuerdo Transpacífico de Cooperación Económica (TPP) y la Asociación de Naciones del Sudeste Asiático (ASEAN), y su correspondencia con los países del G8. Los países (en rojo) se agrupan geográficamente: los países orientados hacia el Pacífico a la derecha, los países europeos a la izquierda y los norteamericanos al centro. Canadá y los EE.UU., de manera predecible, están juntos. Alemania, Italia, Francia y el Reino Unido pertenecen a los mismos dos acuerdos (AECG & EEE), por lo que se encuentran en el mismo punto.
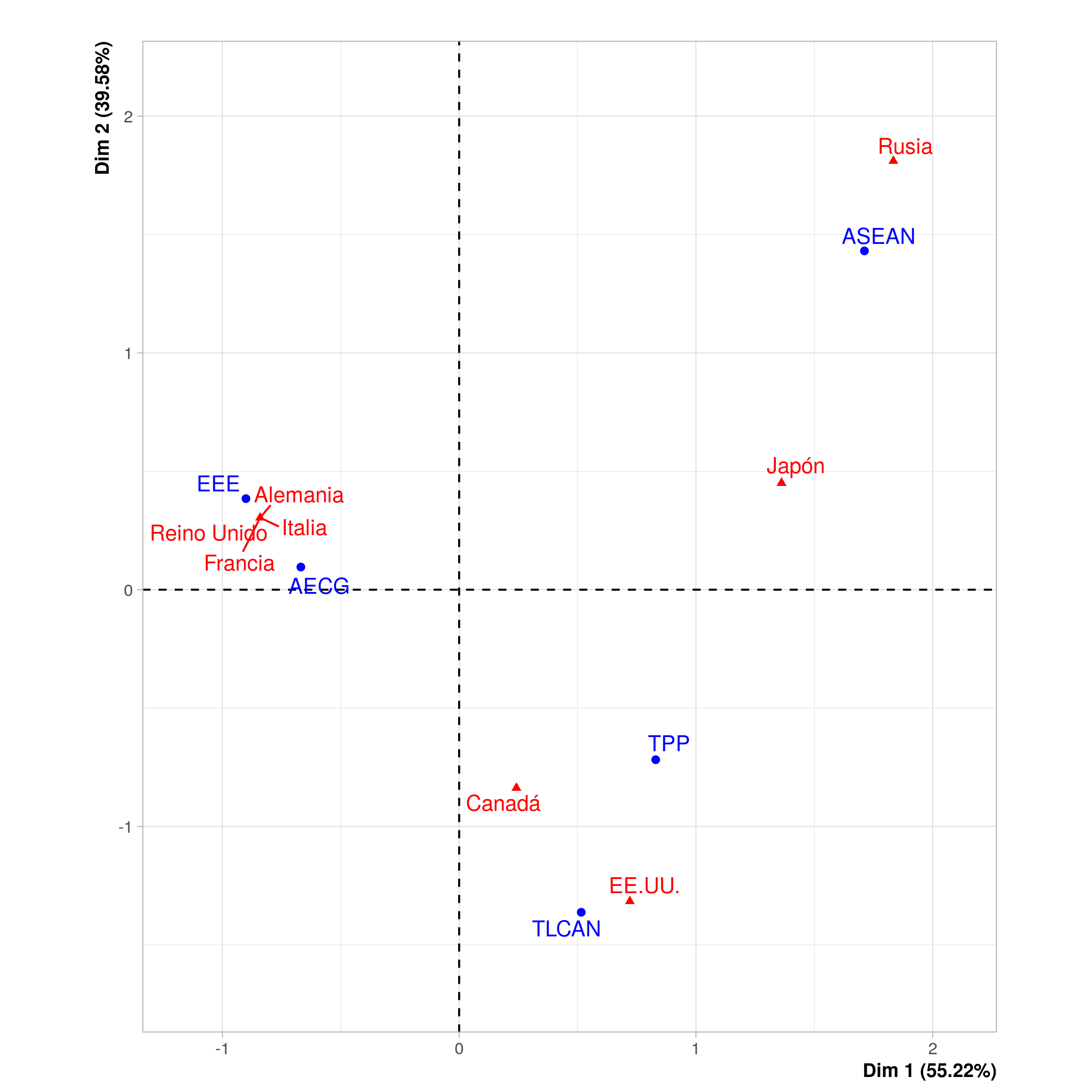
Análisis de correspondencia de una selección de países del G8 y sus tratados de comercio
Por otra parte, aunque Rusia y los EE.UU. están relativamente cerca en el eje horizontal, en el eje vertical se ubican en polos opuestos. Rusia solo comparte un acuerdo comercial con otro país (Japón), mientras que los EE.UU. con dos (Japón y Canadá). En un gráfico de análisis de correspondencia, los elementos con pocas relaciones se ubican en la parte externa, mientras que los que tienen más relaciones lo harán cerca del centro. En el análisis de correspondencia, la conexión relativa o la falta de conexión de un dato se mide como inercia. La relativa falta de conexión produce alta inercia.
Un punto importante sobre Rusia y los EE.UU es que Rusia es un país del Pacífico que no pertenece al TPP. Al observar esa relación, historiadores e historiadoras podrían preguntarse si esto ocurre debido a una relación comercial tensa entre Rusia y EE.UU., comparada con otros países del G8, o debido a actitudes generales hacia los tratados de comercio por parte de estos países. 3
Con más datos, el análisis de correspondencia puede revelar distinciones más sutiles entre grupos dentro de una categoría particular. En este tutorial, daremos una mirada a la vida política de Canadá, específicamente a cómo la representatividad política se organiza en comités en un gobierno respecto de otro. Al igual que con los tratados de comercio, esperaríamos que los comités que tiene más miembros similares estén más cerca. Además, los comités que tienen menos representantes en común se encontrarán en los alrededores del gráfico.
Comités parlamentarios de Canadá
En el sistema parlamentario canadiense la ciudadanía elige representantes llamados Miembros del Parlamento (MP) para la Casa de los Comunes. Los MP son responsables de votar y proponer cambios a la legislación canadiense. Los Comités Parlamentarios (CP) están conformados por MP que informan a la Casa de los Comunes acerca de los detalles importantes de las políticas en un área temática. Ejemplos de este tipo de comités son el de Finanzas, Justicia y Salud.
Usaremos abreviaciones para estos comités porque los nombres a veces son muy largos, lo que hace difícil leerlos en un gráfico. Puedes usar esta tabla como guía de referencia de las abreviaciones.
| Abreviación | Nombre del Comité |
|---|---|
| INDN | Asuntos Indígenas y del Norte |
| RRHH | Recursos Humanos, Habilidades y Desarrollo Social y Situación de las Personas con Discapacidad |
| FINA | Finanzas |
| EXTR | Asuntos Exteriores y Comercio Internacional |
| INFO | Acceso a la Información, Privacidad y Ética |
| MAMB | Medio Ambiente y Desarrollo Sustentable |
| HECA | Herencia Canadiense |
| CINM | Ciudadanía e Inmigración |
| VETE | Asuntos de Veteranos |
| SLUD | Salud |
| TRAN | Transporte, Infraestructura y Comunidades |
| PESQ | Pesquerías y Océanos |
| RRNN | Recursos Naturales |
| SMUJ | Situación de las Mujeres |
| EQUI | Equidad Salarial |
| VCMI | Violencia contra las Mujeres Indígenas |
| BIPA | Biblioteca del Parlamento |
| AGRI | Agricultura y Agroalimentos |
| JUST | Justicia y Derechos Humanos |
Como historiador, mi sospecha es que los MP se organizan según los temas de cada comité de manera distinta de gobierno en gobierno. Por ejemplo, los comités formados durante el primer gabinete del gobierno conservador de Stephen Harper podrían estar organizados de manera distinta a como lo hizo el primer gabinete del liberal Justin Trudeau. Existen razones para esta sospecha. Primero, los CP se forman según liderazgo por partido y las decisiones del comité necesitan coordinación entre los miembros de la Casa de los Comunes. En otras palabras, los partidos políticos usarán a los CP como herramientas para anotar puntos políticos y los gobiernos deben asegurar que las personas correctas sean miembros de los partidos adecuados para proteger sus agendas políticas. Segundo, los dos gobiernos tienen focos políticos diferentes. El gobierno conservador de Harper se enfocó más en asuntos de desarrollo económico, mientras que las primeras grandes decisiones del gobierno liberal de Trudeau enfatizaron la equidad social. En resumen, es posible que hayan algunas decisiones calculadas respecto de quién va a qué comité, lo que provee evidencia sobre las actitudes de un gobierno a favor o en contra de ciertos temas.
Preparando R para el análisis de correspondencia
Para realizar un análisis de correspondencia necesitaremos un paquete que pueda realizar álgebra lineal. Para quienes tengan más inclinación por las matemáticas, en esta lección se incluye un apéndice con algunos detalles sobre cómo se realiza esto. En R, existe una serie de opciones para el AC, pero nosotros utilizaremos el paquete FactoMineR,4 que está enfocado en el “análisis exploratorio de datos multivariados”. FactoMineR puede ser usado para realizar todo tipo de análisis multivariados, incluyendo conglomerados jerárquicos, análisis factorial, etcétera.
Pero primero, así es como se instalan y llaman los paquetes de R, y cómo luego los datos se asignan a un objeto de R para trabajar sobre ellos.
## Estos comandos solo necesitan ser ejecutados la primera vez que se realiza un análisis.
## FactoMineR es un paquete bastante grande, por lo que puede tomar un tiempo en cargarse.
install.packages("FactoMineR") # incluye un módulo para realizar el AC
install.packages("factoextra") # paquete para mejorar la apariencia de los gráficos de AC
# activar los paquetes:
library(FactoMineR)
library(factoextra)
# set.seed(189981) # código opcional para asegurar la reproducibilidad del análisis.
# leer el archivo csv y asignarlo a un objeto en R. Agregamos la opción de encoding a "UTF-8", ya que algunos apellidos tienen tilde.
harper_df <- read.csv("https://raw.githubusercontent.com/programminghistorian/jekyll/gh-pages/assets/correspondence-analysis-in-R/es-translation/HarperCP-es.csv", stringsAsFactors = FALSE, encoding = "UTF-8")
Los datos
Los datos originales de la versión en inglés de este tutorial se encuentran archivados en Zenodo, en caso de que quieras ver los datos brutos. Se han incluido en formato tabular también. En esta traducción al español trabajaremos sobre una versión traducida de los datos (no es necesario que descargues estos archivos de forma manual; los descargaremos directamente usando R):
1) CPCs de Harper 2) CPCs de Trudeau
Revisemos una muestra de los datos de la primera sesión del gobierno de Stephen Harper. Las filas representan los comités y las columnas son los miembros específicos. Si un miembro pertenece a un comité, la celda tendrá un 1; si no pertenece, tendrá un 0.
harper_df
C. Bennett D. Wilks D. V. Kesteren G. Rickford J. Crowder K. Block K. Seeback
EXTR 0 0 1 0 0 0 0
FINA 0 0 1 0 0 0 0
INDN 1 0 0 1 1 0 1
JUST 0 1 0 0 0 0 1
SLUD 0 1 0 0 0 1 0
SMUJ 0 0 0 0 0 0 0
VCMI 1 0 0 1 1 1 0
L. Davies N. Ashton R. Goguen R. Saganash S. Ambler S. Truppe
EXTR 0 0 0 1 0 0
FINA 0 0 0 0 0 0
INDN 0 0 0 0 1 0
JUST 0 0 1 0 0 0
SLUD 1 0 0 0 0 0
SMUJ 0 1 0 0 1 1
VCMI 1 1 1 1 1 1
Estructurada de otra manera (a través de una tabla de R), podemos ver que los comités tienen varios MP y que algunos MP son miembros de múltiples comités. Por ejemplo, la MP liberal Carolyn Bennett fue miembro de “INDN” (Asuntos Indígenas y del Norte) y de “VCMI” (Violencia en contra de las mujeres indígenas), y que “SLUD” (el comité parlamentario de Salud) incluía tanto a D. Wilks como a K. Block. En general, los comités tienen entre nueve y doce miembros. Algunos MP son miembros de un solo comité, mientras otros pueden pertenecer a varios.
Análisis de correspondencia de los comités parlamentarios de Canadá 2006 y 2016.
Nuestro data frame harper_df está compuesto por el nombre completo de los comités y los nombres de los MP. Como algunos nombres de comités son muy largos para que se muestren bien en un gráfico (por ejemplo, “Recursos Humanos, Habilidades y Desarrollo Social y Situación de las Personas con Discapacidad”), usaremos las abreviaciones.
harper_tabla <- table(harper_df$abreviatura, harper_df$miembro)
La función table (tabla) permite crear un conjunto de datos tabulares cruzados a partir de dos categorías de un data frame. Como las columnas corresponden a cada MP y las filas a cada comité, cada celda contiene un 0 o un 1 dependiendo de si la conexión existe. Si miramos la asistencia real a cada reunión, podríamos agregar valores ponderados (por ejemplo, 5 para un MP que asiste a un comité 5 veces). Como regla de oro, se usan valores ponderados cuando las cantidades importan (cuando la gente invierte dinero, por ejemplo), y se usan ceros y unos cuando no.
Desafortunadamente, tenemos un problema más. Un gran número de MP son miembros de un solo comité. Esto puede provocar que esos MP se superpongan cuando creemos el gráfico, haciéndolo menos legible. Pongamos como requerimiento, entonces, que los MP pertenezcan al menos a dos comités antes de ejecutar la función de análisis de correspondencia de FactoMineR.
harper_tabla <- harper_tabla[,colSums(harper_tabla) > 1]
AC_harper <- CA(harper_tabla)
plot(AC_harper, title = "Mapa de factores AC - Harper")
La función colSums suma los valores de cada columna de la tabla. rowSums puede utilizarse para sumar las filas si fuese necesario.
La función CA (análisis de correspondencia, por las siglas en inglés de Correspondence Analysis) grafica los resultados para las dos dimensiones principales y guarda el resumen de los datos en una variable a la que llamamos AC_harper. En gran medida, la función CA hace casi todo el trabajo por nosotros. Agregamos el argumento title = "Mapa de factores AC - Harper" para que el título aparezca en español. Si no incluyes esa línea de código obtendrás el mismo gráfico, pero con el título por defecto en inglés (“CA factor map”). Como se señaló antes, en el apéndice se ofrecen más detalles sobre las matemáticas detrás del AC.
Al ejecutar el código, deberías obtener un gráfico parecido a este:
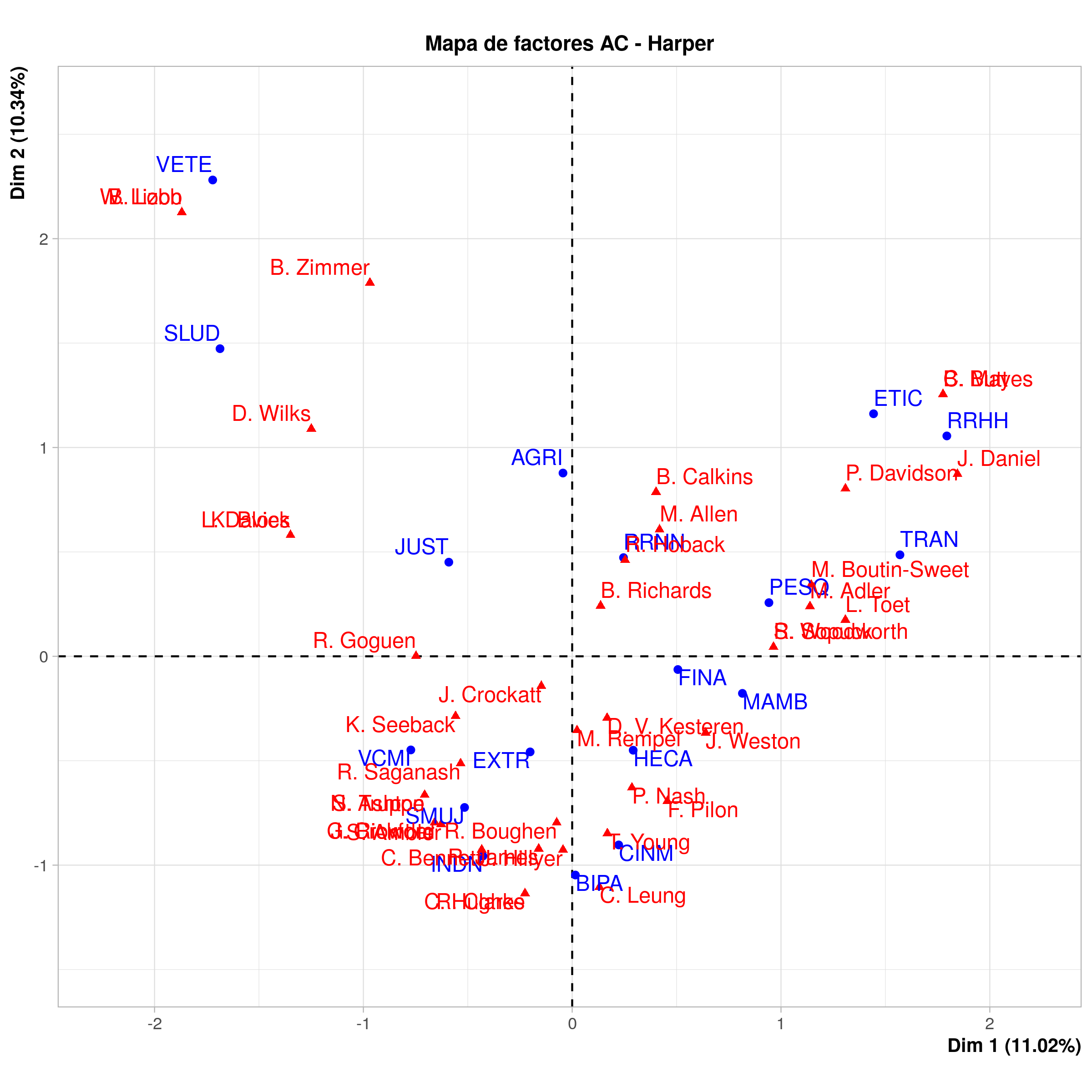
Análisis de Correspondencia de la primera sesión de Comités Parlamentarios del Gobierno de Harper
Procesemos los datos del gobierno de Trudeau de la misma manera:
trudeau_df <- read.csv("https://raw.githubusercontent.com/programminghistorian/jekyll/gh-pages/assets/correspondence-analysis-in-R/es-translation/TrudeauCP-es.csv", stringsAsFactors = FALSE, encoding = "UTF-8")
trudeau_tabla <- table(trudeau_df$abreviatura, trudeau_df$miembro)
trudeau_tabla <- trudeau_tabla[,colSums(trudeau_tabla) > 1]
AC_trudeau <- CA(trudeau_tabla)
plot(AC_trudeau, title = "Mapa de factores AC - Trudeau")
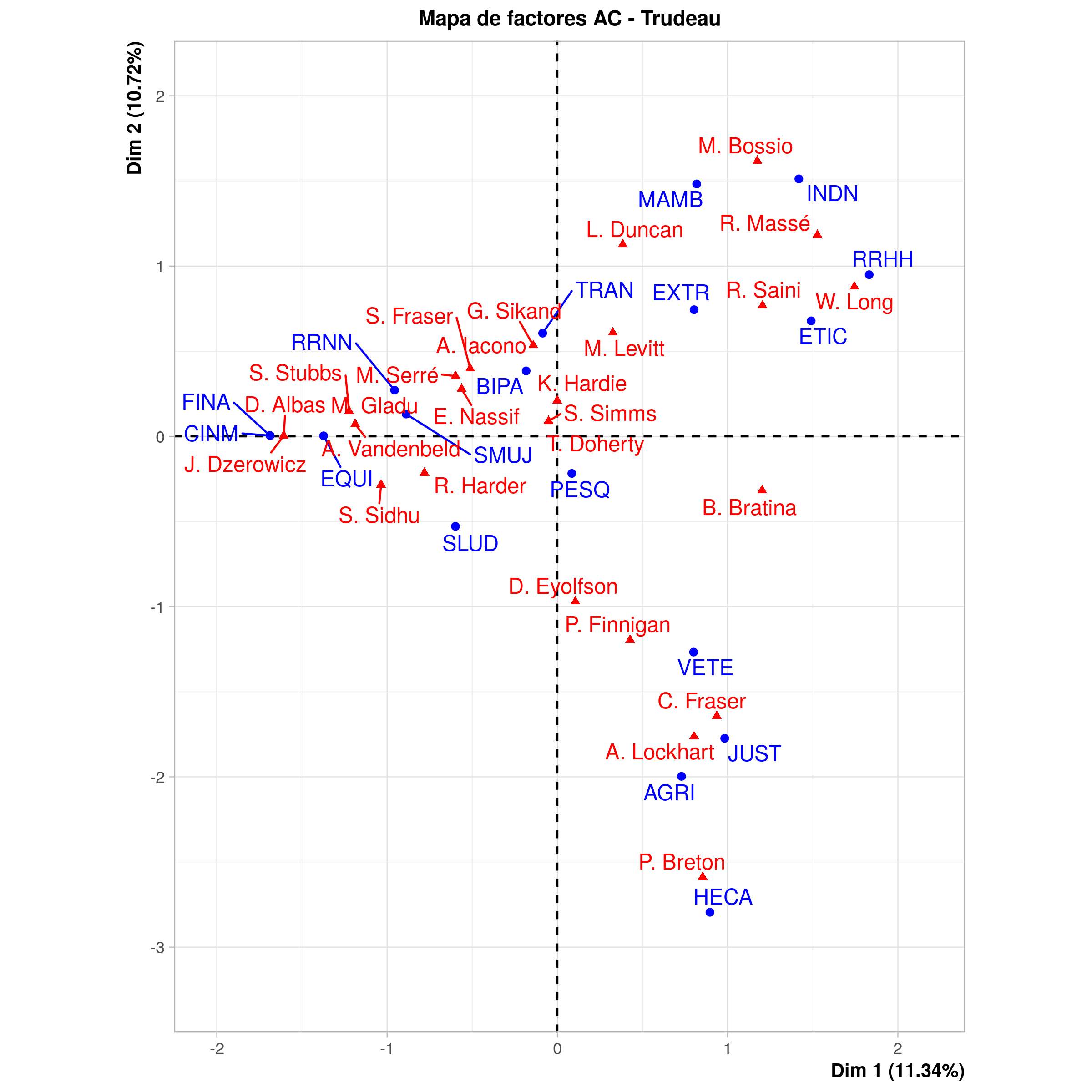
Análisis de Correspondencia de la primera sesión de Comités Parlamentarios del Gobierno de Justin Trudeau
En el caso del gráfico de Harper, las etiquetas de los datos no son muy legibles tal como están. Incluso utilizando las abreviaciones, estas se superponen. El paquete factoextra5 tiene un atributo de repulsión que ayuda a ver las cosas con mayor claridad.
fviz_ca_biplot(AC_harper, repel = TRUE, title = "Mapa de factores AC - Harper")
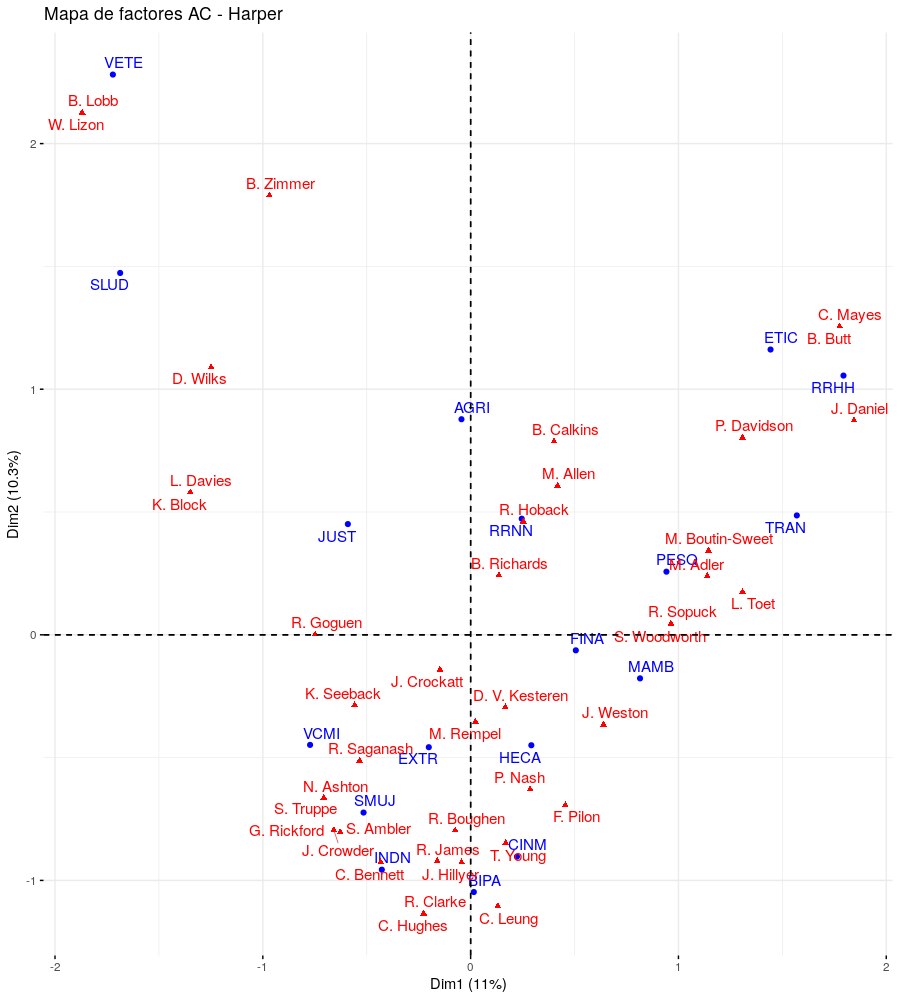
Análisis de Correspondencia de la primera sesión de Comités Parlamentarios del Gobierno de Harper
En vez de superponerse, ahora las etiquetas utilizan flechas para mostrar su ubicación, cuando corresponde.
Interpretación del análisis de correspondencia
Los gráficos con los datos se ven mejor, pero ¿qué tanto podemos confiar en la validez de los resultados? Nuestra primera pista es mirar las dimensiones (ver Dim 1 y Dim 2 en los ejes horizontal y vertical del gráfico). En el AC de los datos de Harper, solo un once y diez por ciento de valor explicativo aparece en los ejes horizontal y vertical,6 lo que da un total ¡de 21 por ciento! Eso no suena muy prometedor para nuestro análisis. Si recordamos que el total del número de dimensiones es igual al número de filas o columnas (la que sea más pequeña), esto puede ser preocupante. Cuando ocurren valores tan bajos, suele significar que que los puntos de datos están distribuidos equitativamente. Que los MP estén distribuidos de manera equitativa en los CP es una convención bastante establecida en el parlamento canadiense.
Otra manera de mirar los datos es a través de los valores de inercia.7 Se pueden encontrar más detalles sobre ella en el apéndice, pero mirando este gráfico, se puede decir que los puntos distantes del origen tienen mayor inercia. Estos puntos sugieren valores fuera de rango, es decir, actores o eventos que tienen que tienen menos conexiones que los que se encuentran en el centro. Los valores bajos, por su parte, sugieren la existencia de puntos de datos que tienen más en común con el grupo como un todo. Como herramienta de análisis, puede ser útil para encontrar actores renegados o subgrupos dentro del conjunto de datos. Si todos los puntos tienen una inercia alta, puede ser indicador de una alta diversidad o fragmentación para las redes. Si es baja puede ser indicador de una mayor cohesión o convergencia general. Lo que esto signifique dependerá del conjunto de datos. En el caso de nuestros gráficos, ningún punto se aventura más allá de dos pasos desde la media. Nuevamente, esto es un indicador de que las relaciones están distribuidas de una forma relativamente equitativa.
Miremos los datos más de cerca:
summary(AC_harper)
El código anterior nos entrega un resumen cuyas primeras filas se ven así:
Call:
CA(X = harper_tabla)
The chi square of independence between the two variables is equal to 655.6636
(p-value = 0.7420958 ).
Eigenvalues
Dim.1 Dim.2 Dim.3 Dim.4 Dim.5 Dim.6
Variance 0.831 0.779 0.748 0.711 0.666 0.622
% of var. 11.024 10.342 9.922 9.440 8.839 8.252
Cumulative % of var. 11.024 21.366 31.288 40.729 49.568 57.820
Dim.7 Dim.8 Dim.9 Dim.10 Dim.11 Dim.12
Variance 0.541 0.498 0.463 0.346 0.305 0.263
% of var. 7.174 6.604 6.138 4.591 4.041 3.488
Cumulative % of var. 64.995 71.599 77.736 82.328 86.368 89.856
Dim.13 Dim.14 Dim.15 Dim.16 Dim.17
Variance 0.240 0.195 0.136 0.105 0.088
% of var. 3.180 2.591 1.807 1.396 1.170
Cumulative % of var. 93.036 95.627 97.434 98.830 100.000
Los Eigenvalues que encabezan el resumen muestran métricas para las nuevas dimensiones calculadas. Desafortunadamente, el porcentaje de varianza encontrada en las dos primeras dimensiones es muy bajo. Incluso si pudiésemos visualizar 7 u 8 dimensiones de los datos, solo podríamos capturar un porcentaje acumulado de alrededor de un 70 por ciento. La prueba de independencia chi cuadrada nos indica que no podemos rechazar la hipótesis de que nuestras dos categorías son independientes. El valor p es 0.74,8 muy por encima del 0.05 que se utiliza habitualmente como punto de corte para rechazar la hipótesis nula. Un valor p más bajo ocurriría, por ejemplo, si todos o la mayor parte de los MP fueran miembros de uno o dos comités. Si bien el valor p de la prueba de chi cuadrada para la muestra de Trudeau es menor (0.54), aún no es lo suficientemente bajo como para rechazar la hipótesis de que son categorías independientes.9
Como ya se discutió, este resultado no es sorprendente. Se espera que los MP estén distribuidos equitativamente entre comités. Si eligiéramos ponderar nuestras medidas basándonos en la asistencia de los MP a cada comité o su deseo de ser miembros de ese comité en una escala de 1 a 100, probablemente veríamos resultados distintos (por ejemplo, probablemente sea más común que los MP asistan regularmente a las reuniones de finanzas que a otras).
¿Nos falló el análisis de correspondencia? No realmente. Esto solo significa que no podemos simplemente lanzarle datos a un algoritmo y esperar que responda preguntas históricas reales. Pero no somos solo programadores, sino historiadores e historiadoras que programan. Así que tenemos que ponernos nuestros “lentes históricos” y ver si podemos refinar nuestra investigación.
¿Expandió Trudeau la agenda sobre equidad para las mujeres en el parlamento?
Una de las primeras movidas políticas que realizó Justin Trudeau fue asegurarse que Canadá tuviese un gabinete conformado en un 50% por mujeres. Puede decirse que el propósito de este anuncio era declarar una agenda de igualdad de género. El gobierno de Trudeau también creó en su primera sesión un nuevo Comité Parlamentario por la igualdad de pago para las mujeres. Además, su gobierno introdujo una moción para investigar la desaparición y asesinato de mujeres indígenas, que reemplazó al comité parlamentario de Harper sobre violencia en contra de las mujeres indígenas.
Si Trudeau pretendía tomarse en serio la igualdad para las mujeres, deberíamos esperar que más miembros del Comité sobre Estado de las Mujeres estén conectados con carteras como Justicia, Finanzas, Salud y Asuntos Exteriores, respecto del gobierno de Harper. Como el mandato de Harper no tenía un CP sobre equidad salarial, incluiremos el CP de Violencia contra las mujeres Indígenas.
# incluir solo los comités que nos interesan
# SLUD: Salud, JUST: Justicia, SMUJ: Situación de las mujeres,
# INDN: Asuntos Indígenas y del Norte, FINA: Finanza
# EXTR: Asuntos Exteriores y Comercio Internacional
# VCMI: Violencia contra las Mujeres Indígenas
harper_df2 <- harper_df[which(harper_df$abreviatura %in% c("SLUD", "JUST", "SMUJ", "INDN", "FINA", "EXTR", "VCMI")),]
harper_tabla2 <- table(harper_df2$abreviatura, harper_df2$miembro)
# remover a quienes solo participan en un comité
harper_tabla2 <- harper_tabla2[, colSums(harper_tabla2) > 1]
AC_harper2 <- CA(harper_tabla2)
plot(AC_harper2, title = "Mapa de factores AC - Harper")
Esto genera el siguiente gráfico:
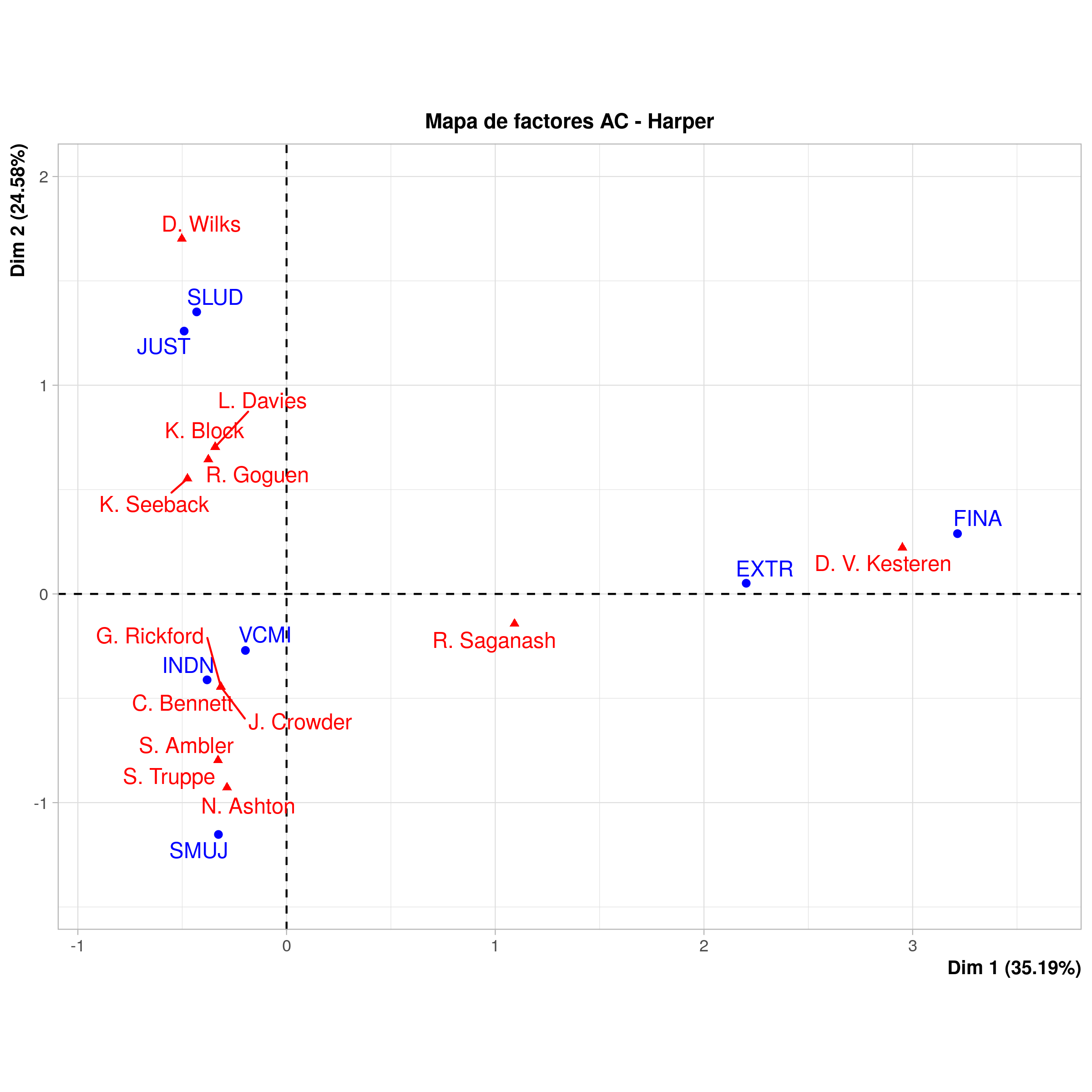
Análisis de correspondencia de las comisiones parlamentarias seleccionadas para la primera sesión del gobierno de Stephen Harper
El valor p de la prueba de chi cuadrada para este análisis solo se mueve levemente hacia el cero, a 0,71. Todavía no podemos sacar ninguna conclusión cuantitativa sobre una clara relación entre CP y MP. Para nuestros datos, esto no es tan importante como resultado. Quizás si sondeáramos a los MP sobre qué CP fue el más productivo o importante, encontraríamos valores p más bajos. La inercia sobre el eje horizontal casi se duplicó, lo que sugiere que FINA (Finanzas) es un valor fuera de rango en el gráfico en comparación con otras carteras.
El significado de un análisis de correspondencia depende de la interpretación cualitativa que se haga del gráfico. Al mirar los elementos del gráfico de Harper, por ejemplo, podríamos decir que las preocupaciones económicas caen hacia la derecha del eje y que las preocupaciones sociales hacia la izquierda. Por lo que una de las “razones” para escoger a los MP que participan en los comités durante el gobierno de Harper pareciera ser distinguir entre preocupaciones sociales y económicas.
Sin embargo, cuando ejecutamos el mismo análisis para el gobierno de Trudeau…
trudeau_df2 <- trudeau_df[which(trudeau_df$abreviatura %in% c("SLUD", "JUST", "SMUJ", "INDN", "FINA", "EXTR", "EQUI")),]
trudeau_tabla2 <- table(trudeau_df2$abreviatura, trudeau_df2$miembro)
trudeau_tabla2 <- trudeau_tabla2[, colSums(trudeau_tabla2) > 1] # remueve los únicos (singles) de nuevo
AC_trudeau2 <- CA(trudeau_tabla2)
plot(AC_trudeau2)
obtenemos una advertencia junto con el gráfico.
Warning message:
In CA(trudeau_tabla2) :
The rows EXTR, INDN, JUST sum at 0. They were suppressed from the analysis
Este mensaje nos está indicando que no existen relaciones cruzadas entre algunos de los comités. Si miramos el objeto trudeau_tabla2, vemos lo siguiente:
A. Vandenbeld D. Albas M. Gladu R. Harder S. Sidhu
EQUI 1 1 1 0 1
EXTR 0 0 0 0 0
FINA 0 1 0 0 0
INDN 0 0 0 0 0
JUST 0 0 0 0 0
SLUD 0 0 0 1 1
SMUJ 1 0 1 1 0
¡No hay membresías cruzadas entre Asuntos Extranjeros, Asuntos Indígenas y del Norte o Justicia! Bueno, solo esto ya es un resultado en sí mismo. Podemos concluir, de manera general, que las agendas de los dos gobiernos son bastante diferentes y que hubo aproximaciones distintas respecto de cómo organizar a los MP en comités. Para la historia de Canadá, este resultado hace sentido, considerando que Violencia contra las Mujeres Indígenas es mucho más probable que esté conectado con Asuntos Indígenas y del Norte y con el Departamento de Justicia (la historia del comité Violencia contra las Mujeres Indígenas está vinculada a un número de casos criminales de alta connotación en Canadá), que con Equidad Salarial. Como se discutió anteriormente, el análisis de correspondencia requiere de una cuota de interpretación para que sea significativo.
Quizás podríamos mirar algunos comités diferentes. Si sacamos “JUST”, “INDN” y “EXTR”, y los reemplazamos por “CINM” (Ciudadanía e Inmigración), “ETIC” (Ética y Acceso a la Información) y “RRHH” (Recursos Humanos), podemos tener finalmente una visión de la estructura de los comités parlamentarios en este contexto.
trudeau_df3 <- trudeau_df[which(trudeau_df$abreviatura %in% c("SLUD", "CINM", "SMUJ", "ETIC", "FINA", "RRHH", "EQUI")),]
trudeau_tabla3 <- table(trudeau_df3$abreviatura, trudeau_df3$miembro)
trudeau_tabla3 <- trudeau_tabla3[, colSums(trudeau_tabla3) > 1] # remueve los únicos (singles) de nuevo
AC_trudeau3 <- CA(trudeau_tabla3)
plot(AC_trudeau3, title = "Mapa de factores AC - Trudeau")
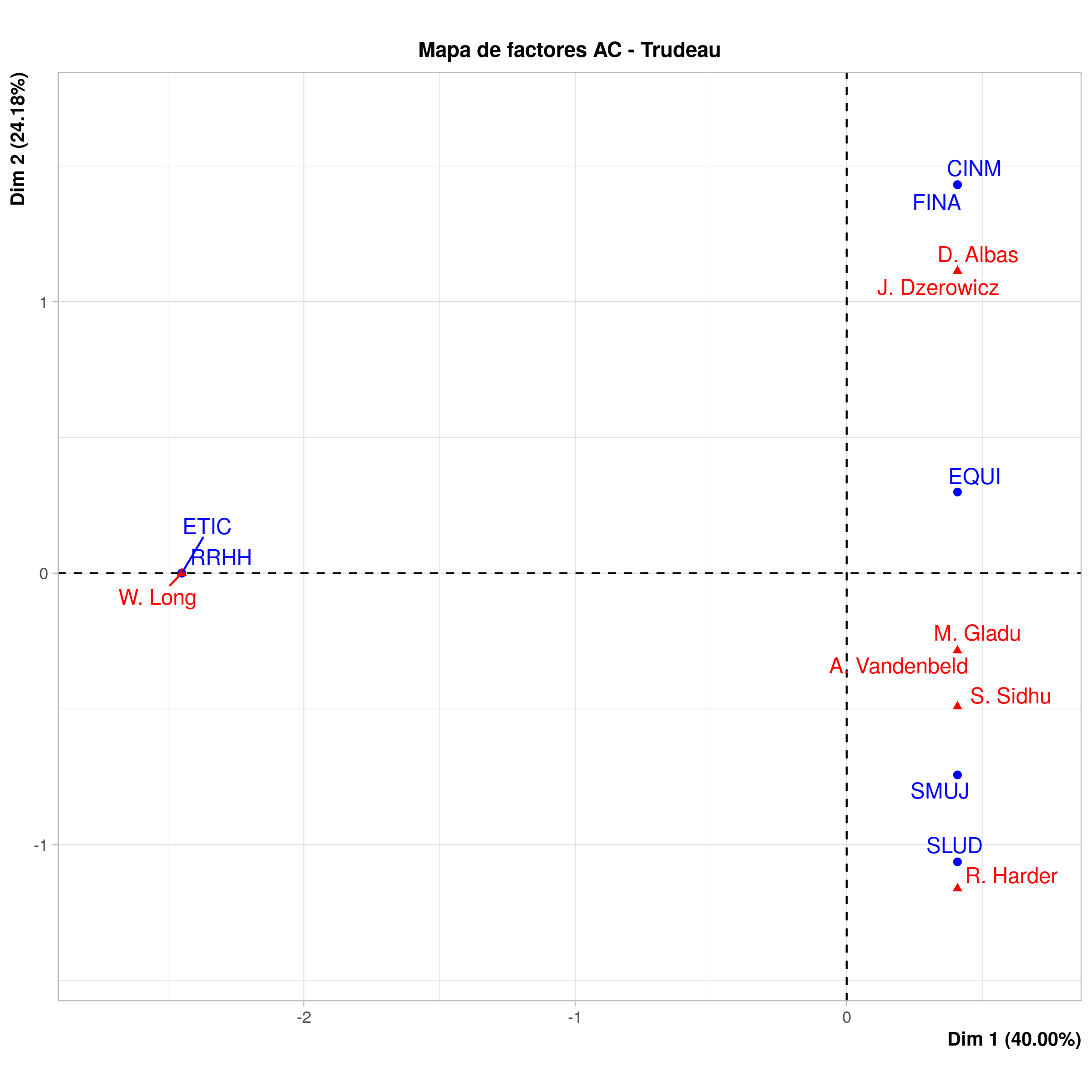
Análisis de correspondencia de las comisiones parlamentarias seleccionadas para la primera sesión del gobierno de Justin Trudeau
En general, la inercia sobre el eje horizontal es menos que la del gobierno de Harper, pero la separación tiene a RRHH (Recursos Humanos) y ETIC (Ética) en oposición a las otras carteras en la derecha. La demarcación entre temas sociales y económicos no es tan evidente como en el caso de Harper, lo que sugiere una filosofía distinta para la selección. Además, hay menos MP compartiendo las posiciones. Ese puede ser otro misterio para exploraciones futuras. Pese a eso, el proceso llevado a cabo con el análisis de correspondencia nos dio una sólida panorámica sobre las relaciones que ocurren dentro de los comités de un vistazo rápido, con muy pocos comandos.
Análisis
Como en la mayoría de la investigación interpretativa, no obtuvimos una respuesta unívoca a nuestra pregunta sobre el poder para las mujeres en los gobiernos parlamentarios. En el caso de Harper, vemos una división entre asuntos sociales, como Salud y Justicia, y asuntos económicos, como Finanzas y Relaciones Exteriores, que da cuenta del 35% de la varianza. De la visualización podemos suponer que Finanzas (FINA) y Asuntos Exteriores (EXTR) tienen un miembro en común y que Asuntos Exteriores (EXTR) tiene un miembro en común con Violencia Contra la Mujer Indígena (VCMI). Este resultado es posiblemente de interés, ya que las agendas más publicitadas de Stephen Harper tendieron a enfocarse en preocupaciones económicas como comercio y control fiscal. La separación de los comités sugiere que la filosofía de gobierno de Harper separaba las preocupaciones económicas de las sociales, y que los derechos de las mujeres eran principalmente una preocupación de tipo social. La cartera de Situación de las Mujeres (SMUJ) aparece separada del resto de las carteras y se encuentra conectada con otras solo a través de MP comunes con los comités de Violencia contra las Mujeres Indígenas (VCMI) y Asuntos Indígenas y del Norte (INDN).
Los gráficos del gobierno de Trudeau no muestran conexiones cruzadas entre la cartera de Situación de las Mujeres y Justicia, Asuntos Exteriores y Personas Indígenas, pero sí conexiones con Finanzas, Ciudadanía, Recursos Humanos y Ética. Situación de las Mujeres está conectada con Finanzas e Inmigración a través de la cartera de Equidad Salarial.
Puede decirse, entonces, que el gobierno de Harper alineó los derechos de las mujeres con carteras sociales, tales como Justicia y Salud, mientras que Trudeau elevó el perfil de Situación de las Mujeres hasta cierto punto al incluir el comité de Equidad Salarial. La conexión entre comités focalizados en los derechos de la Mujer y carteras fuertes como Salud, Finanzas y Ciudadanía e Inmigración en el gobierno de Trudeau merece un análisis más detallado. El comité de Situación de las Mujeres, en este contexto, parece poseer un posición más central (cercana al origen) en el gobierno de Trudeau que en el gobierno de Harper. Dicho esto, el número de puntos de datos en este caso sigue siendo bastante pequeño para derivar una conclusión definitiva. Tal vez otras fuentes podrían ser visualizadas en forma similar para confirmar o negar este punto.
La agenda previamente sostenida entre mujeres y pueblos indígenas ha sido remplazada en el caso de Trudeau. Tal como se revisó anteriormente, la Investigación Nacional sobre Mujeres y Niñas Indígenas Desaparecidas y Asesinadas sustituyó el mandato del comité sobre la Violencia Contra Mujeres Indígenas que existió durante el gobierno de Harper. La historia de este reemplazo es compleja, pero, en pocas palabras, el gobierno de Harper vivió presiones políticas para crear la Investigación Nacional sobre Mujeres y Niñas Indígenas Desaparecidas y Asesinadas a partir del juicio a Robert Pickton y los reportes de que las investigaciones policiales eran insuficientes en el caso de mujeres indígenas desaparecidas. Harper se rehusó a realizar un Comité de Investigación diciendo que el CP era la mejor aproximación.10 Trudeau hizo la promesa de campaña de incluir esta investigación y, por tanto, desplazar así al CP. En cierto grado, pareciera que Harper le dió un rol bastante central a la Violencia contra Mujeres Indígenas en la planificación de los comités parlamentarios. Esta evidencia es un contrapunto a las críticas de que Harper no se tomó con seriedad el problema de las mujeres indígenas desaparecidas y asesinadas.
Las diferencias entre las dos relaciones levanta importantes preguntas sobre el rol de la situación de la mujer en el discurso político y sus interconexiones entre la identidad racial, finanzas públicas, salud y justicia social. Sería interesante, tal vez, explorar estas en mayor detalle en trabajos cualitativos. También plantea importantes preguntas sobre un enfoque de género en general (según la cartera de Situación de la Mujer) o, más específicamente, en lo que respecta a un grupo marginalizado (Mujeres Indígenas Desaparecidas y Asesinadas). Un artículo de política relacionado con los beneficios de una investigación versus una discusión del Comité Parlamentario parece razonable luego de haber examinado esta evidencia. Tal vez existe un argumento que exponga que el cambio de VCMI por EQUI es una especie de tejado de vidrio, en tanto coloca artificialmente una cuota sobre los problemas de las mujeres mientras carteras establecidas permanecen intactas. Como una herramientas exploratoria, el AC ayuda a identificar tales temas a través de observaciones empíricas, más que a través de la teoría o sesgos personales.
Conclusión
Ahora que este tutorial está completo, deberías tener alguna idea sobre qué es el análisis de correspondencia (AC) y cómo puede ser utilizado para responder preguntas exploratorias sobre los datos. Usamos la función CA del paquete FactoMineR para crear el análisis y graficar los resultados en dos dimensiones. Cuando las etiquetas se superpusieron, aplicamos la función viz_ca_biplot del paquete factoextra para desplegar los datos en un formato más legible.
También aprendimos cómo interpretar un AC y cómo detectar posibles errores analíticos, incluyendo casos en el que las relaciones entre categorías están distribuidas uniformemente y tienen un bajo valor explicativo. En este caso, refinamos nuestra pregunta de investigación y nuestros datos para proveer de una imagen más significativa sobre qué estaba pasando.
En general, el beneficio de esta análisis es entregar un resumen rápido de dos sets de datos categóricos como un paso inicial para problemáticas históricas más sustantivas. El uso de miembros y reuniones o eventos en todas las áreas de la vida (negocios, organizaciones sin fines de lucro, reuniones municipales, hashtags de twitter, etcétera) es una aproximación común para este análisis. Los grupos sociales y sus preferencias es otro uso común del AC. En cada caso, la visualización ofrece un mapa con el cual observar una fotografía de la vida social, cultural y política.
El siguiente paso debería incluir la adición de más dimensiones categóricas para nuestro análisis, tal como la incorporación de partidos políticos, edad o género. Al AC con más de dos categorías, se le conoce como un Análisis de Correspondencia Múltiple o MCA, por sus siglas en inglés. Si bien las matemáticas del MCA son más complicadas, el resultado final es bastante similar al CA.
Por suerte, ahora puedes aplicar estos métodos a tus propios datos, ayudándote a dejar al descubierto preguntas e hipótesis que enriquezcan tu investigación histórica. ¡Buena suerte!
Apéndice: Las matemáticas detrás del Análisis de Correspondencia
Dado que las matemáticas del CA será de interés para algunas personas pero no para otras, las he incluido en este apéndice. Esta sección también contiene un poco más de detalles sobre otros temas como inercia, dimensiones y descomposición en valores singulares (SVD)
Para que sea más fácil de entender, comenzaremos solo con algunos comités: SMUJ (Situación de las Mujeres), SLUD (Salud), INDN (Asuntos Indígenas y del Norte), VCMI (Violencia contra las Mujeres Indígenas) y JUST (Justicia y Derechos Humanos).
C. Bennett D. Wilks G. Rickford J. Crowder K. Block K. Seeback L. Davies N. Ashton
INDN 1 0 1 1 0 1 0 0
JUST 0 1 0 0 0 1 0 0
SLUD 0 1 0 0 1 0 1 0
SMUJ 0 0 0 0 0 0 0 1
VCMI 1 0 1 1 1 0 1 1
R. Goguen S. Ambler S. Truppe
INDN 0 1 0
JUST 1 0 0
SLUD 0 0 0
SMUJ 0 1 1
VCMI 1 1 1
El Análisis de Correspondencia está hecho sobre un set de datos “normalizado” que es creado a través de la división del valor de cada celda por la raíz cuadrada del producto de los totales de la columna y fila,11 o celda \(\frac{1}{\sqrt{total columna \times total fila}}\). Por ejemplo, la celda para FEWO y S Ambler es \(\frac{1}{\sqrt{3 \times 3}}\) o 0.333.
La tabla normalizada luce así:
C. Bennett D. Wilks G. Rickford J. Crowder K. Block K. Seeback L. Davies N. Ashton
INDN 0.316 0.000 0.316 0.316 0.000 0.316 0.000 0.000
JUST 0.000 0.408 0.000 0.000 0.000 0.408 0.000 0.000
SLUD 0.000 0.408 0.000 0.000 0.408 0.000 0.408 0.000
SMUJ 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.408
VCMI 0.235 0.000 0.235 0.235 0.235 0.000 0.235 0.235
R. Goguen S. Ambler S. Truppe
INDN 0.000 0.258 0.000
JUST 0.408 0.000 0.000
SLUD 0.000 0.000 0.000
SMUJ 0.000 0.333 0.408
VCMI 0.235 0.192 0.235
El proceso de normalización hace algo interesante. Quienes son miembros de múltiples comités y/o quienes pertenecen a comités con muchos miembros tenderán a tener puntajes normalizados más bajos. Esto nos sugiere que estos miembros son más centrales en la red. Es decir, estos miembros serán puestos más hacia el centro de la matriz. Por ejemplo, la celda que pertenece a S. Ambler y SMUJ tiene 0.192, el puntaje más bajo, debido a que S. Ambler es un miembro de tres comités y el comité VCMI tiene nueve miembros en el gráfico representado.
El próximo paso es encontrar la descomposición en valores singulares de estos datos normalizados. Esto implica un álgebra lineal bastante compleja que no será revisada acá, pero sobre la que puedes aprender más en este tutorial sobre descomposición en valores singulares (en inglés) o ver más detalles en este documento pdf sobre SVD (en inglés).12 Intentaré resumir qué ocurre en términos sencillos.
- Dos nuevas matrices que muestran puntajes de “dimensión” para las filas (comités) y las columnas (MP) son creadas a partir de eigenvectors
- El número de dimensiones es igual al tamaño de las columnas o filas menos 1; la que sea más pequeña. En este caso, hay cinco comités comparados con los 11 MP, por lo que el número de dimensiones es cuatro
- Una matriz adicional muestra los eigenvalues, que pueden ser usados para mostrar la influencia de cada dimensión en el análisis
- Uno de varios “tratamientos” es aplicado a los datos para hacerlos más fáciles de graficar. El más común es el enfoque de “coordenadas estándar” (standard coordinates), que compara cada puntaje normalizado positiva o negativamente con el puntaje promedio
Usando coordenadas estándar, nuestra tabla de datos muestra lo siguiente:
Columns (MPs):
Dim 1 Dim 2 Dim 3 Dim 4
C. Bennett -0.4061946 -0.495800254 0.6100171 0.07717508
D. Wilks 1.5874119 0.147804035 -0.4190637 -0.34058221
G. Rickford -0.4061946 -0.495800254 0.6100171 0.07717508
J. Crowder -0.4061946 -0.495800254 0.6100171 0.07717508
K. Block 0.6536800 0.897240970 0.5665289 0.04755678
K. Seeback 0.5275373 -1.245237189 -0.3755754 -0.31096392
L. Davies 0.6536800 0.897240970 0.5665289 0.04755678
N. Ashton -0.8554566 0.631040866 -0.6518568 0.02489229
R. Goguen 0.6039463 -0.464503802 -0.6602408 0.73424971
S. Ambler -0.7311723 -0.004817303 -0.1363437 -0.30608465
S. Truppe -0.8554566 0.631040866 -0.6518568 0.02489229
$inertia
[1] 0.06859903 0.24637681 0.06859903 0.06859903 0.13526570 0.17971014 0.13526570
[8] 0.13526570 0.13526570 0.08438003 0.13526570
Rows (Committees):
Dim 1 Dim 2 Dim 3 Dim 4
INDN -0.3705046 -0.8359969 0.4856563 -0.27320374
JUST 1.1805065 -0.7950050 -0.8933999 0.09768076
SLUD 1.2568696 0.9885976 0.4384432 -0.28992174
SMUJ -1.0603194 0.6399308 -0.8842978 -0.30271466
VCMI -0.2531830 0.1866016 0.1766091 0.31676507
$inertia
[1] 0.31400966 0.36956522 0.24927536 0.09017713 0.36956522
Cada puntaje para una “dimensión” puede ser usado como una coordenada en un gráfico. Dado que no podemos visualizar en cuatro dimensiones, los outputs de un CA, usualmente se enfocan en las primeras dos o tres dimensiones para producir el gráfico (por ejemplo, SLUD será graficado sobre [1.245, 0.989] o [1.245, 0.989, 0.438] en un gráfico 3D).
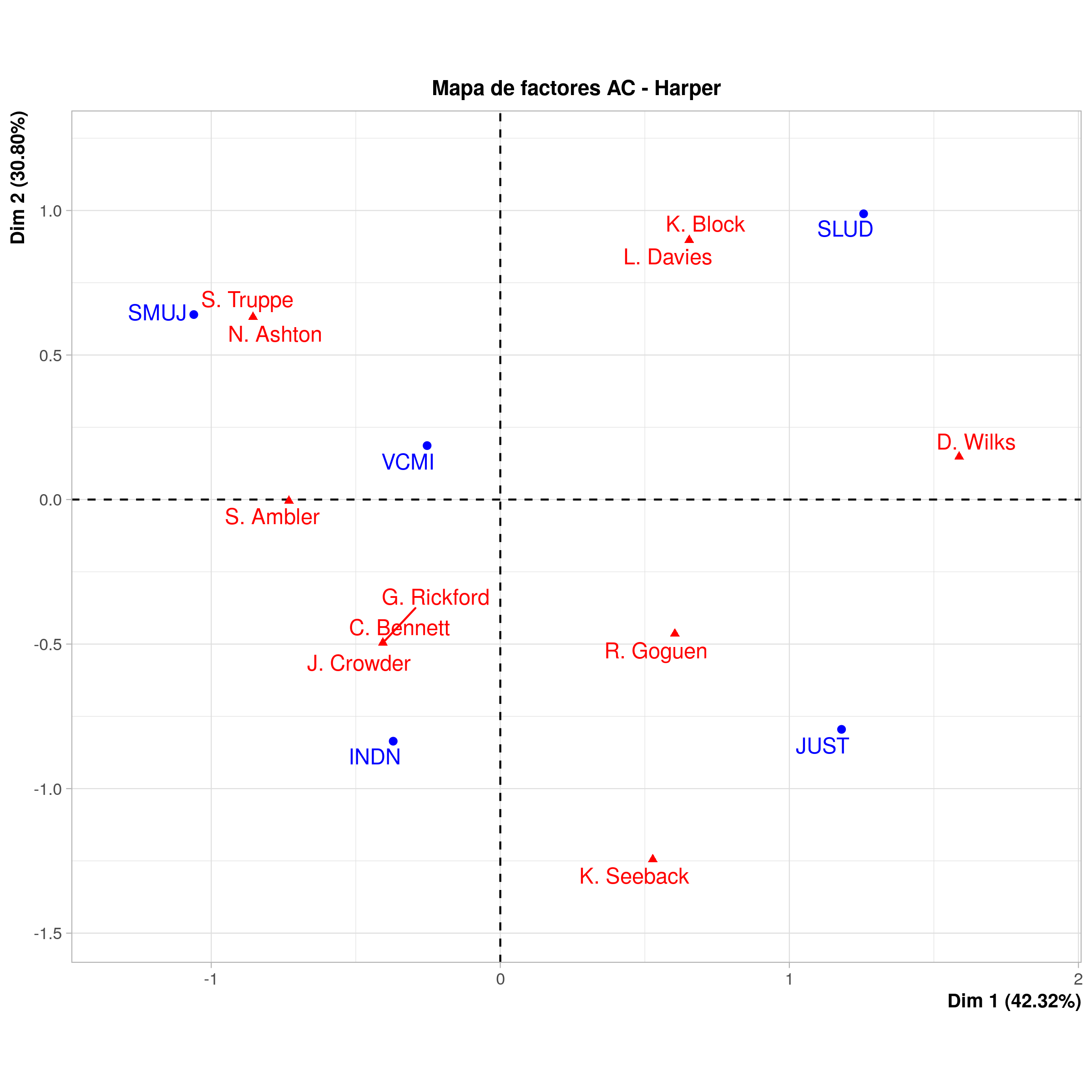
Análisis de correspondencia de las comisiones parlamentarias seleccionadas para la primera sesión del gobierno de Stephen Harper, 2006
Los puntajes de inercia son una forma de mostrar varianza en los datos. Salud y Justicia, teniendo la menor cantidad de miembros, tienen un alto puntaje de inercia, mientras que el comité más popular (VCMI) tiene una inercia pequeña. Por tanto, la inercia es una forma de cuantificar la distancia de los puntos desde el centro del gráfico.
Otro puntaje importante es visible en el gráfico CA: el porcentaje de valor explicativo para cada dimensión. Esto significa que el eje horizontal explica el 43.32 por ciento de la varianza en el gráfico, mientras que el eje vertical explica casi el 31 por ciento. El significado de estos ejes debe ser interpretado basado en el gráfico. Por ejemplo, podríamos decir que el lado izquierdo representa problemas concernientes a la identidad social y aquellos a la derecha son de tipo regulatorio. Un análisis histórico adicional de las actas de estos comités podría a su vez ofrecer una mayor comprensión sobre lo que significaba la participación de estos miembros en ese momento.
Notas finales
-
El AC tiene una historia que se ramifica de varias disciplinas y, por lo tanto, la terminología puede ser confusa. Para simplificar, categorías se refiere a los tipos de datos que se comparan (por ejemplo, Miembros y clubs), mientras que cada elemento dentro de esas categorías (por ejemplo, “El club de tenis” o “John McEnroe”) será un elemento dentro de esa categoría. La ubicación cuantitativa de los elementos (coordenadas x e y) son puntos de datos. ↩
-
Brigitte Le Roux and Henry Rouanet, Multiple Correspondence Analysis (Los Angeles: SAGE Publications, 2010), pg. 3; ↩
-
No quisiera sugerir que este análisis sea de alguna manera concluyente sobre las relaciones comerciales entre Estados Unidos y Rusia. El caso es que debido a que Rusia no es parte del TPP en este acuerdo, se separa de Estados Unidos. Por otro lado, si se pudiera demostrar que la membresía al TPP representa lazos tensos entre Estados Unidos y Rusia, aparecería en el gráfico de AC. ↩
-
Sebastien Le, Julie Josse, Francois Husson (2008). FactoMineR: An R Package for Multivariate Analysis. Journal of Statistical Software, 25(1), 1-18.10.18637/jss.v025.i01. ↩
-
Alboukadel Kassambara and Fabian Mundt (2017). factoextra: Extract and Visualize the Results of Multivariate Data Analyses. R package version 1.0.4. https://CRAN.R-project.org/package=factoextra. ↩
-
Un valor explicativo hace referencia a la distancia de los puntos de datos respecto del centro del gráfico. Cada dimensión da cuenta de parte de la distancia en que los puntos de datos divergen del centro. ↩
-
En general, en estadística el término inercia hace referencia a la variación o “extensión” de un conjunto de datos. Es análoga a la desviación estándar en la distribución de datos. ↩
-
En estadística, un valor p, una abreviación para valor de probabilidad, es un indicador de qué tan probable es que un determinado resultado haya ocurrido por azar. Un valor p bajo sugiere una baja probabilidad de que el resultado sea producto del azar y, por lo tanto, entrega evidencia de que la hipótesos nula, (en este caso, que los MP y los CP son categorías independientes) es poco probable. ↩
-
Dado que este valor p no es menor que 0.05, no puede rechazarse la hipótesis nula. Es decir, que no tenemos evidencia suficiente para decir que existe una asociación entre que dado un cierto MP, estará en un cierto Comité. ↩
-
Ver Laura Kane (April 3, 2017), “Missing and murdered women’s inquiry not reaching out to families, say advocates.” CBC News Indigenous. http://www.cbc.ca/news/indigenous/mmiw-inquiry-not-reaching-out-to-families-says-advocates-1.4053694 ↩
-
Katherine Faust (2005) “Using Correspondence Analysis for Joint Displays of Affiliation Network” in Models and Methods in Social Network Analysis eds. Peter J. Carrington, John Scott and Stanley Wasserman. ↩
-
Otros recursos que podrían ser útiles para aprender sobre SVD son los siguientes: este tutorial en inglés que utiliza ejemplos en R, este tutorial en inglés que explica las matemáticas detrás del AC usando R y esta serie de videos en inglés de YouTube sobre SVD. ↩